Knowledge Distribution¶
- CodeScene measures several aspects of knowledge distribution:
Key personnel risks: Are there any critical parts of the codebase that are in the head of just one developer?
Low system mastery: What’s the impact if a developer leaves or moves to a different product line? Can you continue to successfully maintain the codebase?
Coordination bottlenecks: Are there any parts of the code where multiple teams have to coordinate their work? Such modules frequently lead to waste via merge conflicts and tend to be defect dense.
This guide shows you how to measure these aspects of your software development.
How Do We Measure Knowledge?¶
The knowledge metrics are based on the amount of code each developer has contributed. CodeScene looks at the deep history of each file to calculate contributions. This makes sense for two different reasons:
The last snapshot of a source code file wouldn’t be good enough since such shallow ownership is sensible to superficial changes (e.g. re-formatting issues, automated renaming of variables, etc).
Even if one developer completely rewrites a piece of code, its original author will still retain some knowledge in that area since they’re familiar with the problem domain. The metrics in CodeScene acknowledge that and will retain some knowledge for the original developer as well.
CodeScene uses the name of each committer to calculate knowledge metrics. So please make sure you understand the possible biases discussed in the guide Know the possible Biases in the Data.
Detect Knowledge Risks¶
CodeScene’s dashboard presents a high-level summary of the knowledge distribution and existing knowledge loss (e.g. code written by developers who have since left the company or project):
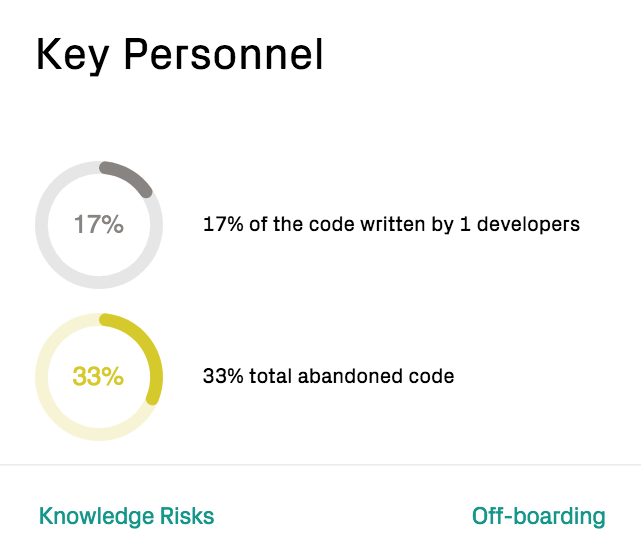
Fig. 142 Dashboard summary of the knowledge distribution.¶
A high portion of code written by a smaller group of people might be a risk; when a core developer leaves, the knowledge loss increases and the lower system mastery makes it more risky to maintain the system. Using the Knowledge Risk view, you can identify those areas pro-actively:
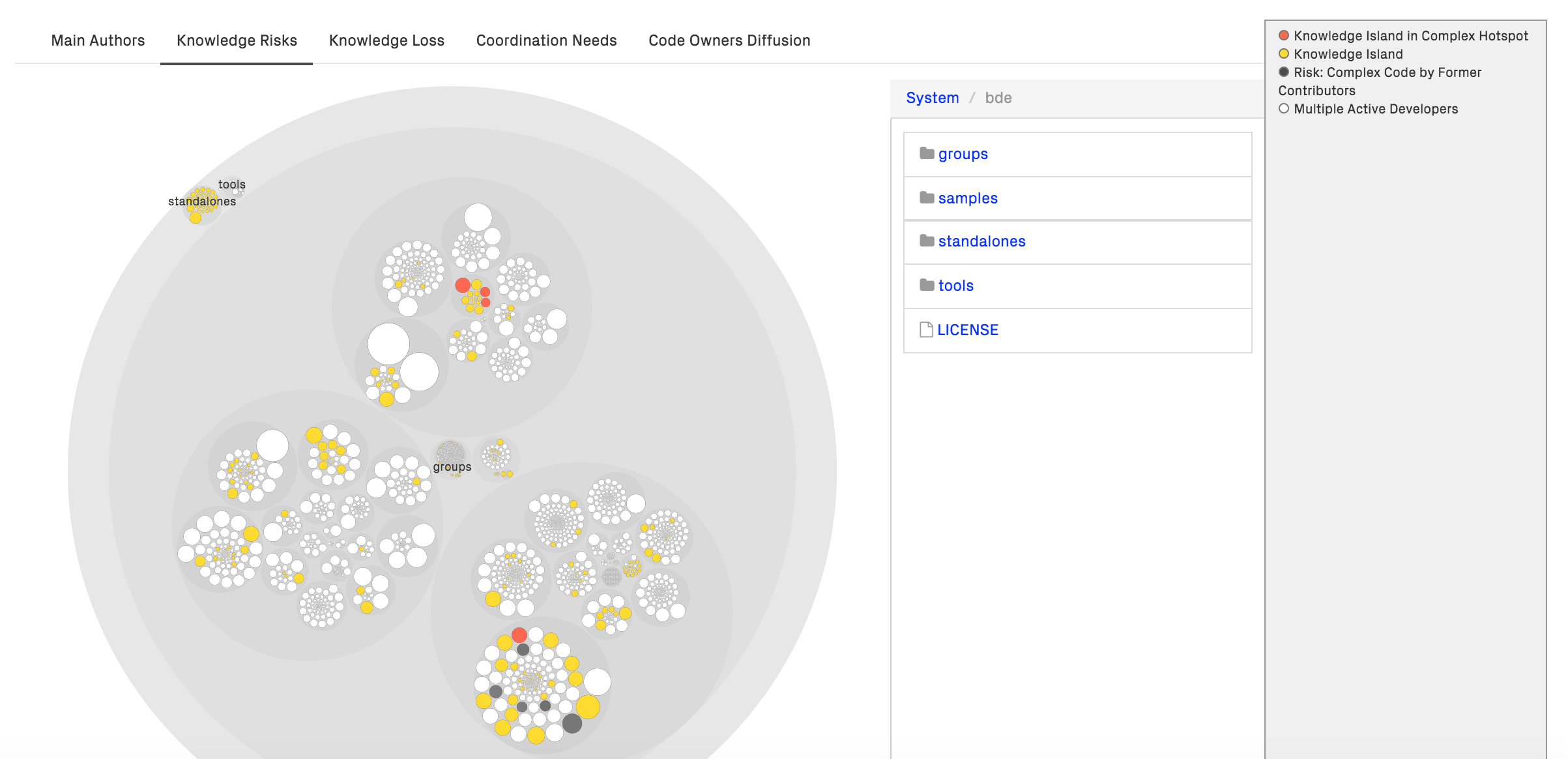
Fig. 143 Identify risks in the knowledge distribution.¶
The Knowledge Risks analysis identifies and highlights the following patterns:
Knowledge Island in Complex Hotspot: A module that’s written mostly by one developer, and that module is a hotspot with code health issues. Consider to on-board at least one more person in these areas as these hotspots present a significant key personnel risk.
Knowledge Island: A knowledge island is code written mostly by one developer, but the code is of acceptable code health. You might still face a key personnel risk, but on-boarding new personnel in this area should be lower risk than in complex hotspots. Make sure that knowledge islands are supervised using CodeScene’s goals (see Manage Hotspots and Technical Debt with Goals).
Complex Code by Former Contributors: This type represents code with low code health, where the majority of that code is written by former contributors. It’s code with low system mastery. Modifying such code is always an increased risk, so make sure to schedule additional time for learning.
Multiple Active Developers: This type indicates that the code is actively worked on and that the detailed knowledge is shared by at least two developers.
Finally, note that CodeScene also presents warnings for knowledge risks as part of the virtual code review.
Explore the Individual Knowledge Map¶
In the interactive knowledge mpas, each color is used to represent the primary author behind a module.
CodeScene allows you to dynamically filter by authors and/or teams:
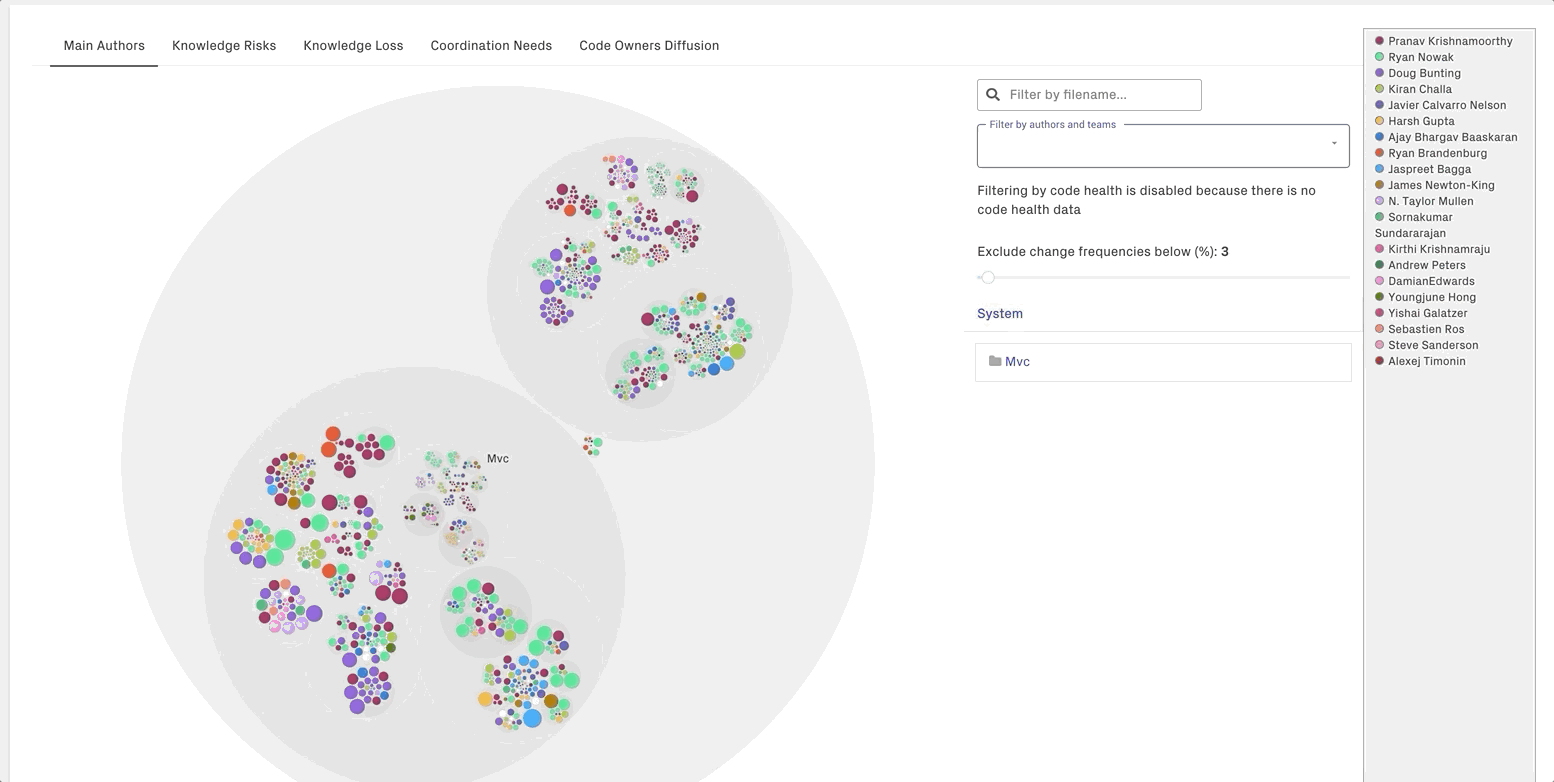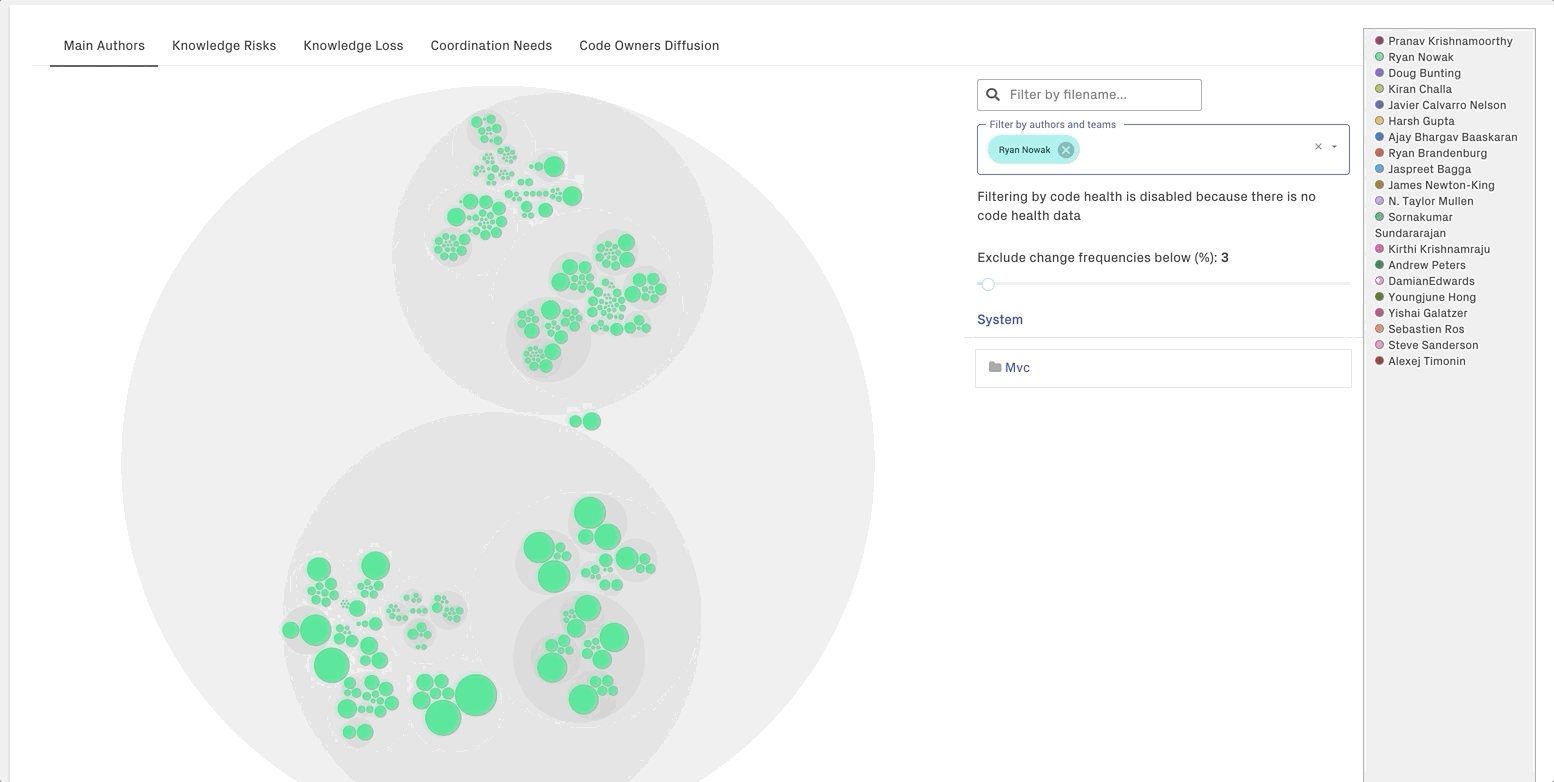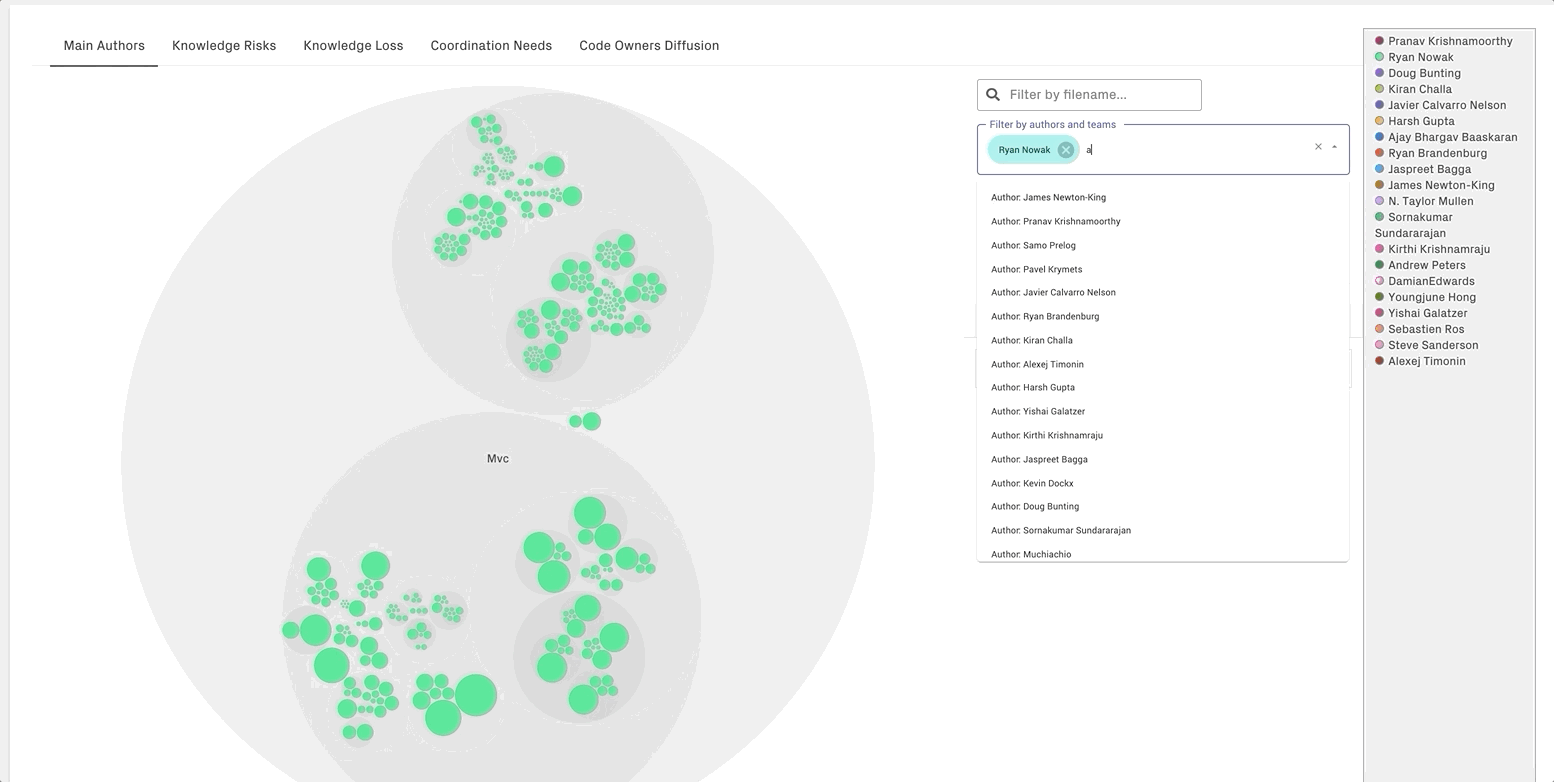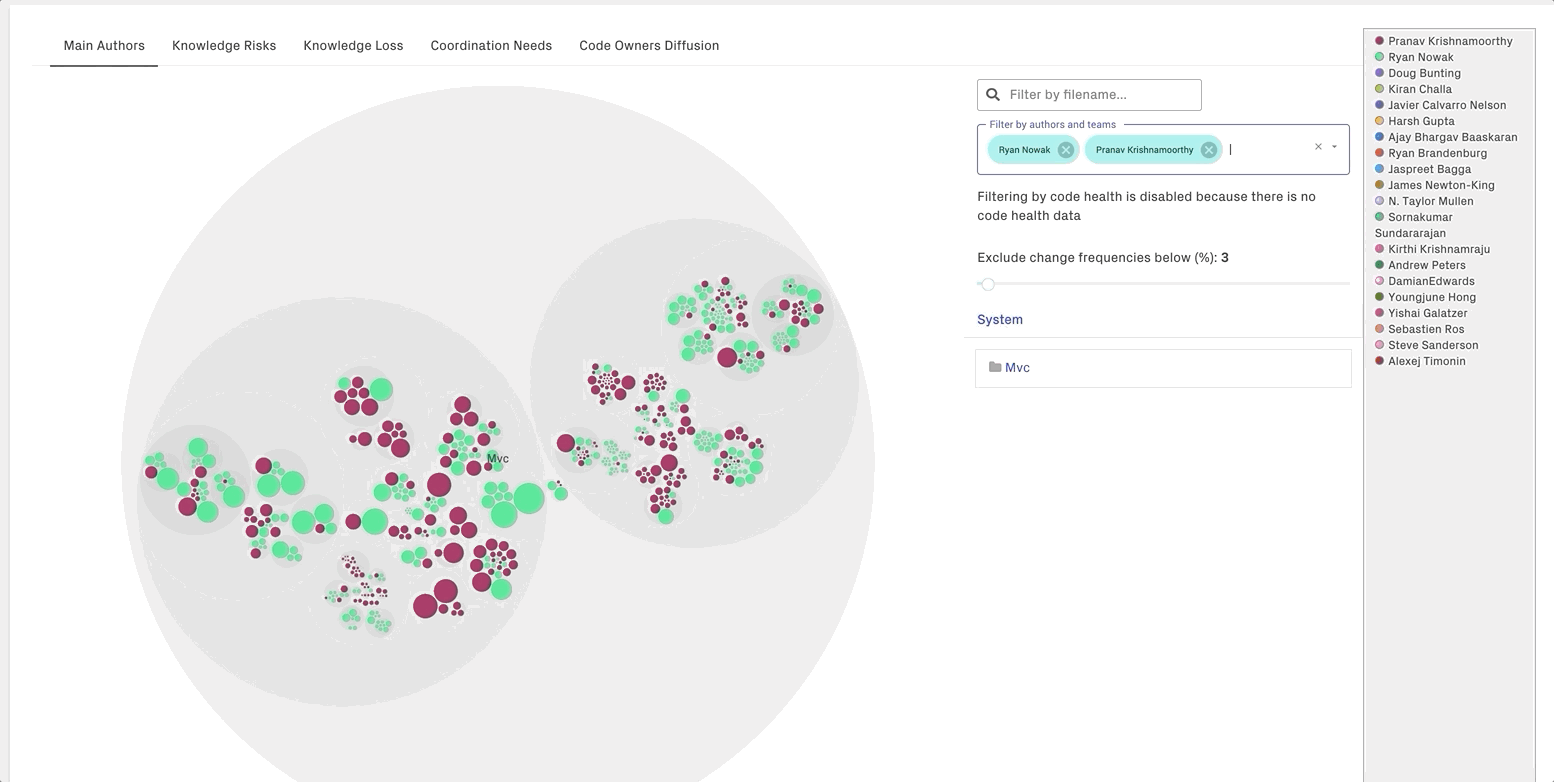
Tip: The knowledge maps are an excellent on-boarding support that helps new team members identify the colleagues that know that most about a particular piece of code. CodeScene’s knowledge maps go way deeper than a plain git blame and will present a more accurate picture of the primary authors.
In case of multiple authors, you click on a file – represented as a cicle in the visualizations – and explore who the other authors are:
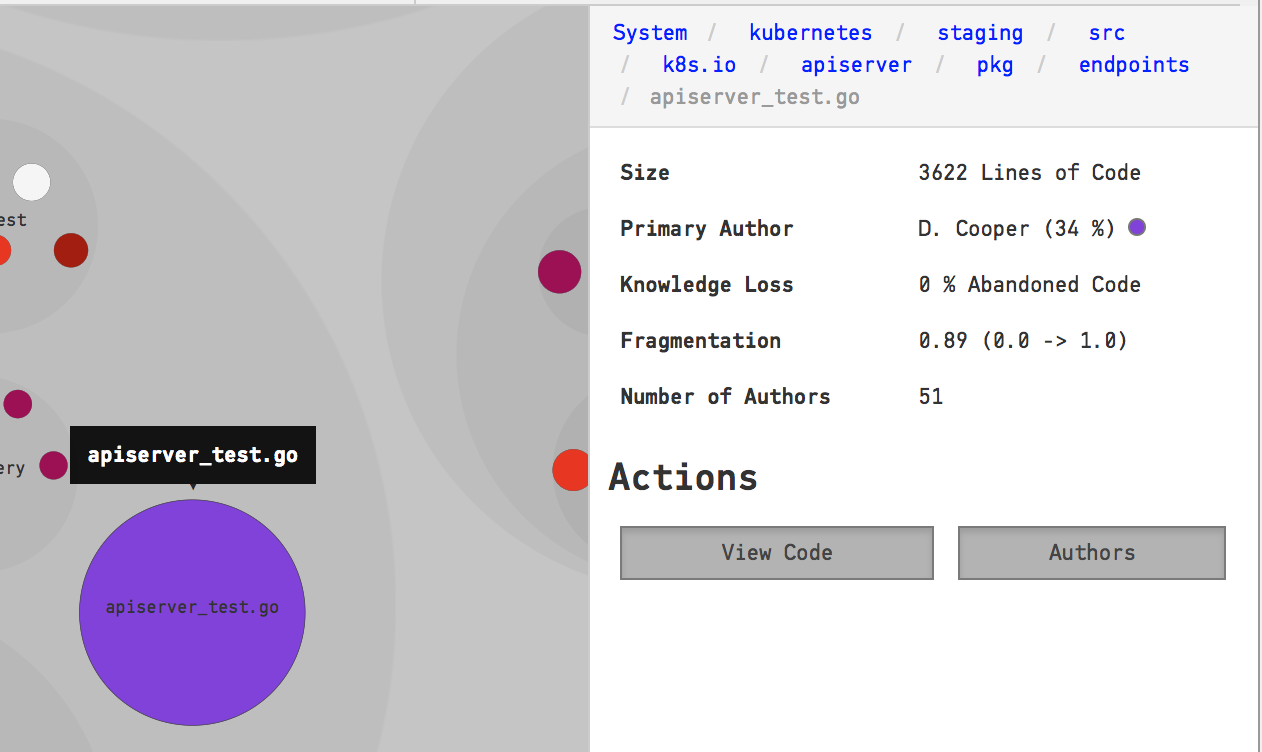
Fig. 144 Inspect the details of each file in the knowledge map.¶
Make sure Pair Programming is configured if needed¶
CodeScene also supports knowledge maps for pair- and mob programming, where the credits are split between the contributors in the pair. However, you need to configure your pair programming patterns in CodeScene to activate this feature. Refer to in Configure Teams and Developers for the configuration options.
Explore your Team Knowledge Maps¶
CodeScene also measures knowledge distribution on a team level and this information is usually even more valuable than the individual metrics.
As soon as you’ve assigned developers to a team, as described in Configure Teams and Developers, CodeScene will accumulate their individual knowledge into their teams. The analysis results are presented using the same principles as for the Individual Knowledge Map. Only now, each color represents a team as shown in Fig. 145.
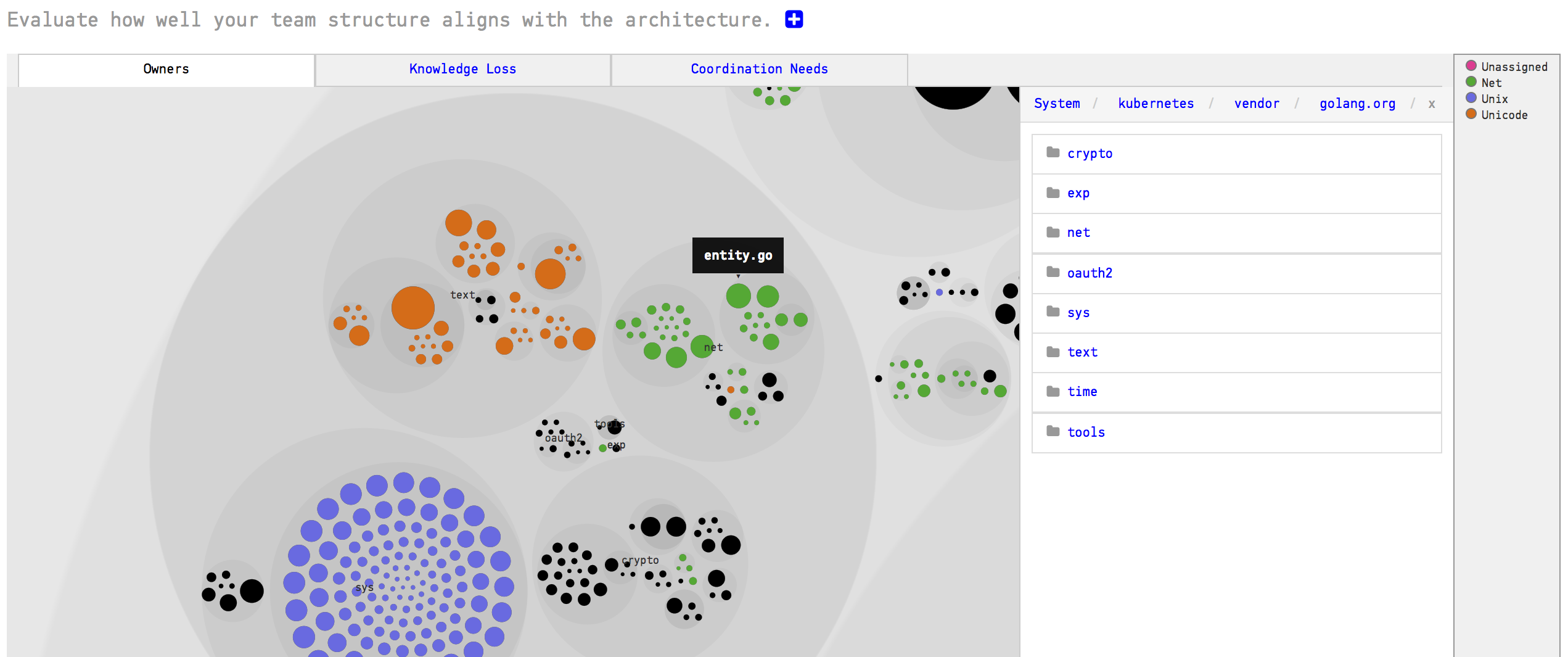
Fig. 145 The distribution of your teams in the codebase.¶
The Team Knowledge Map lets you reason about both the responsibilities of the different teams. In general, you want to ensure that your team organization is reflected in the software architecture of your system. For example, the analysis in Fig. 145 has a configuration for three devlopment teams: Net, Unix, and Unicode. The analysis shows that each time has a clear area of responsibility. However, you get more details by clicking on the Coordination Needs aspect as shown in Fig. 146.
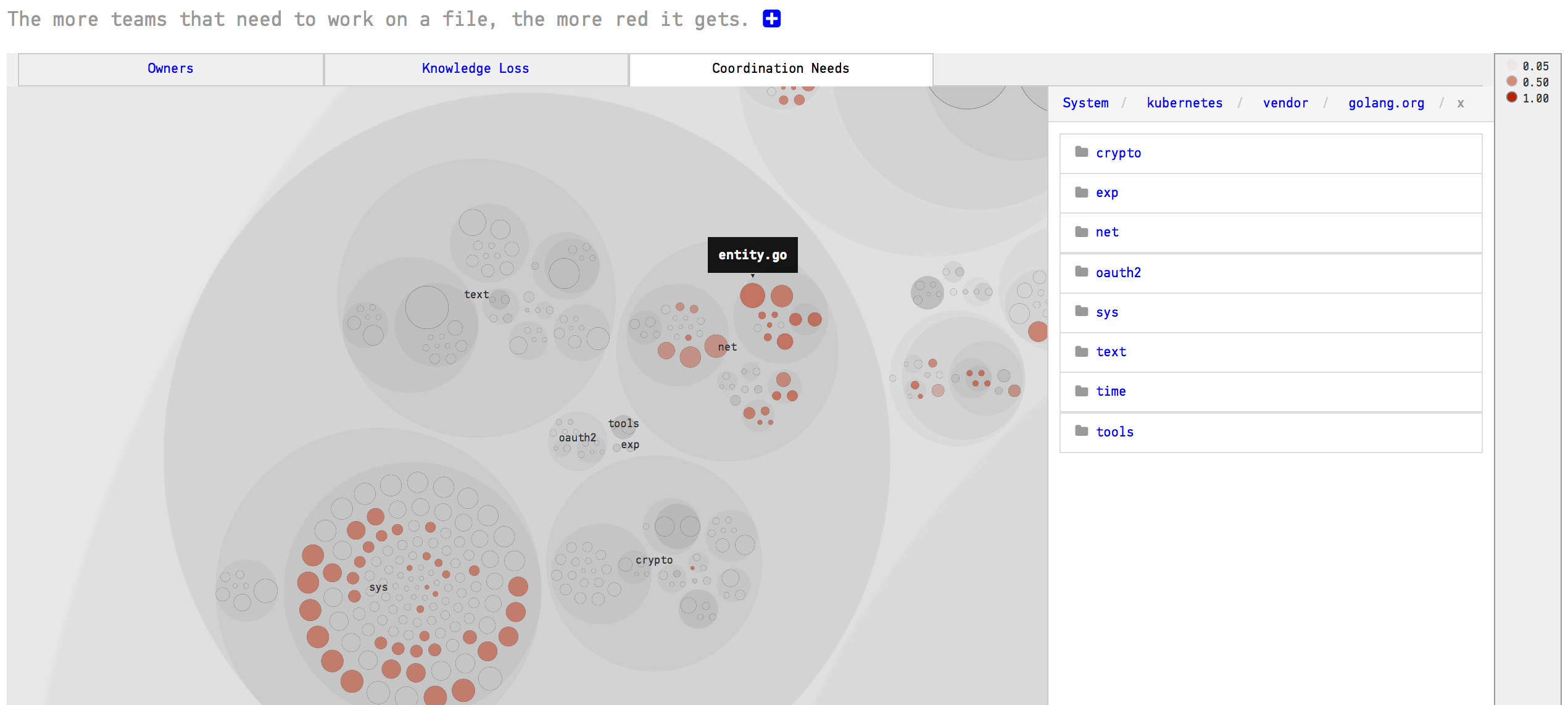
Fig. 146 The coordination needs between your development teams.¶
The coordination analysis shows you the parts of the code where multiple teams have to coordinate their work. From here you can explore which teams that are involved. The coordination analysis is also described in more detail in Parallel Development and Code Fragmentation.
Finally, make sure to read the discussions in the guide Social Networks for more information on the organizational theories and how they correlate to the quality and efficiency of your organization.
Measure from the date of the last organizational change¶
Development organizations aren’t static. People rotate teams, new teams are formed, and old ones abandoned. Each change introduces a possible bias into the team-level metrics.
The best way to avoid those biases is to select an analysis start date that represents the date of your last organizational change. For example, let’s say you changed the team structure back in January 2017. In that case you want to start your team analysis from that date, as illustrated in Fig. 147.
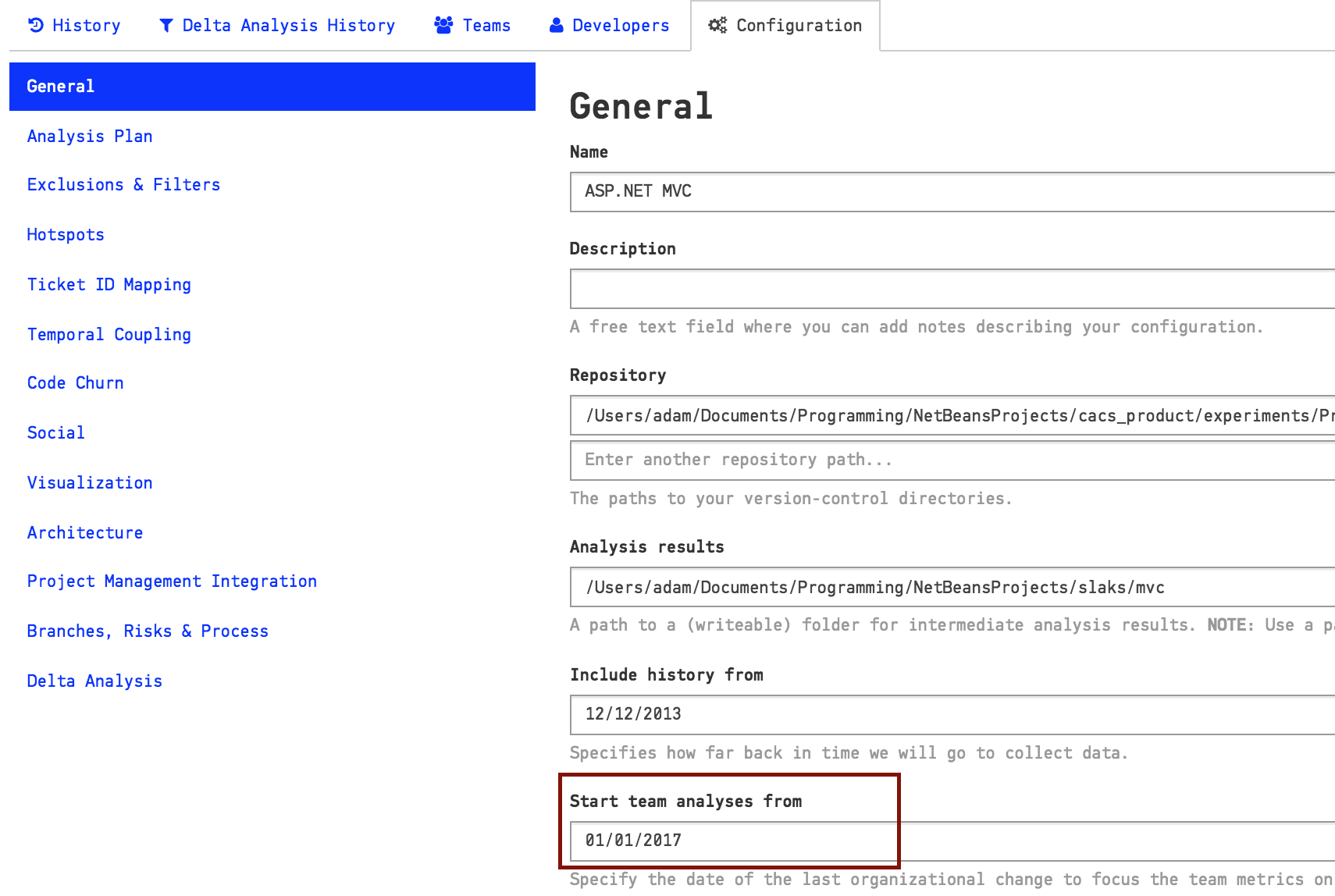
Fig. 147 The coordination needs between your development teams.¶
Note that you typically want to use a longer analysis time span for technical analyses. CodeScene resolves this by letting you configure two separate time spans, as illustrated in Fig. 147.
Visualize Code Ownership Patterns¶
Many Git hosting platforms (e.g. GitHub, GitLab, BitBucket) support the concept of CODEOWNERS. CODEOWNERS is a file where your organization can specify code owners for different parts of your codebase. The ownership is specified by using a set of glob patterns that match different modules, file types, or specific content. Here’s an example:
# Specify the default owners in case the specific patterns
# given later won't match:
* @TheArchitect @TheMicroManager
# The last matching pattern gets precedence, so here
# we specify the owners for invidual sub-systems:
/src/frontend @js-owner
src/backend @go-owner
docs/* @TechWriter
In this examples, the hypothetical user names @TheArchitect, @js-owner, etc. would match real people in your organization. You can of course also specify e-mail addresses instead of user handles.
If you have a CODEOWNERS file, CodeScene will include it in the analysis. You just need to specify that path to the file since it might vary.
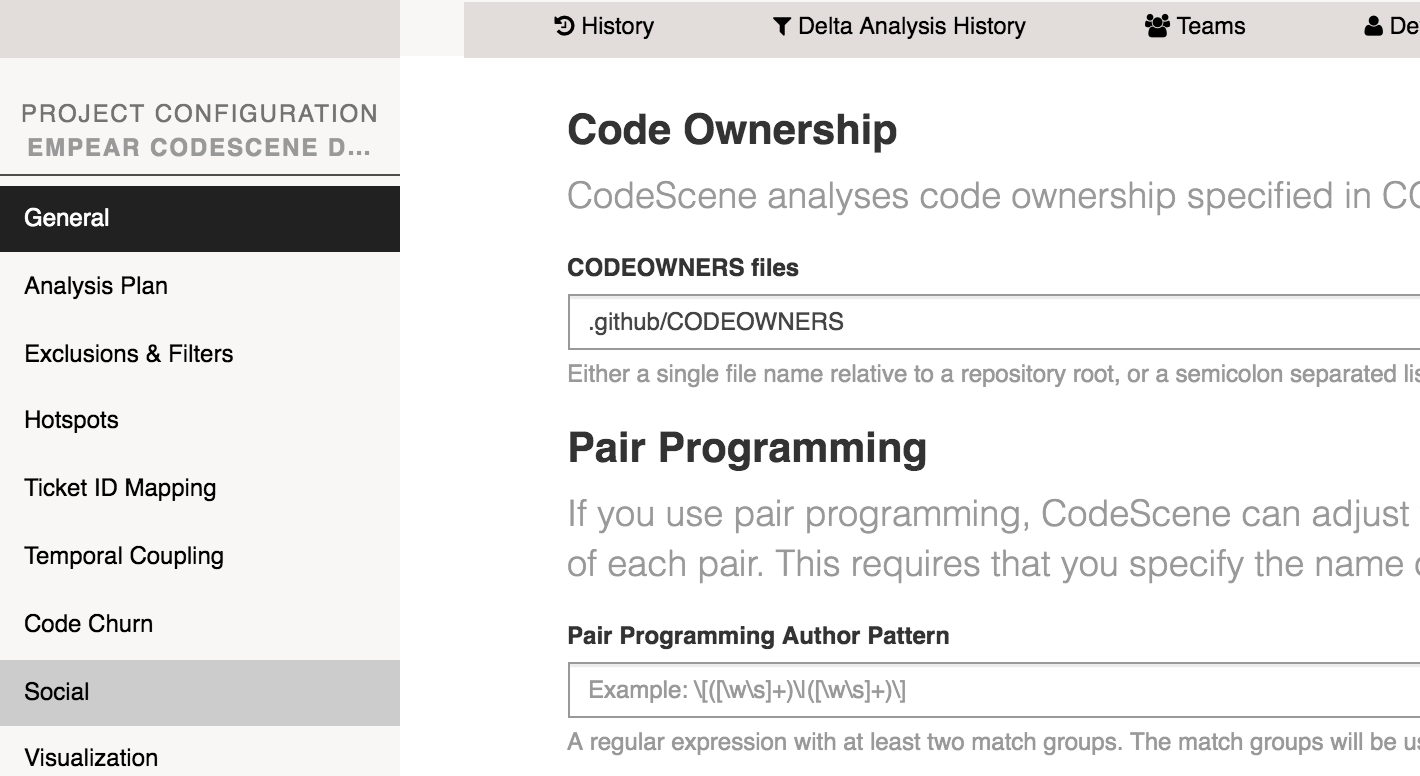
Fig. 148 Specify the relative path to the CODEOWNERS file.¶
In a multi-repository analysis project you might of course have multiple CODEOWNERS files. That’s OK. Should they be in different relative locations, then you just specify all options using a semicolon separated list.
CodeScene will now mine and aggregate the code ownership as shown in Fig. 149.
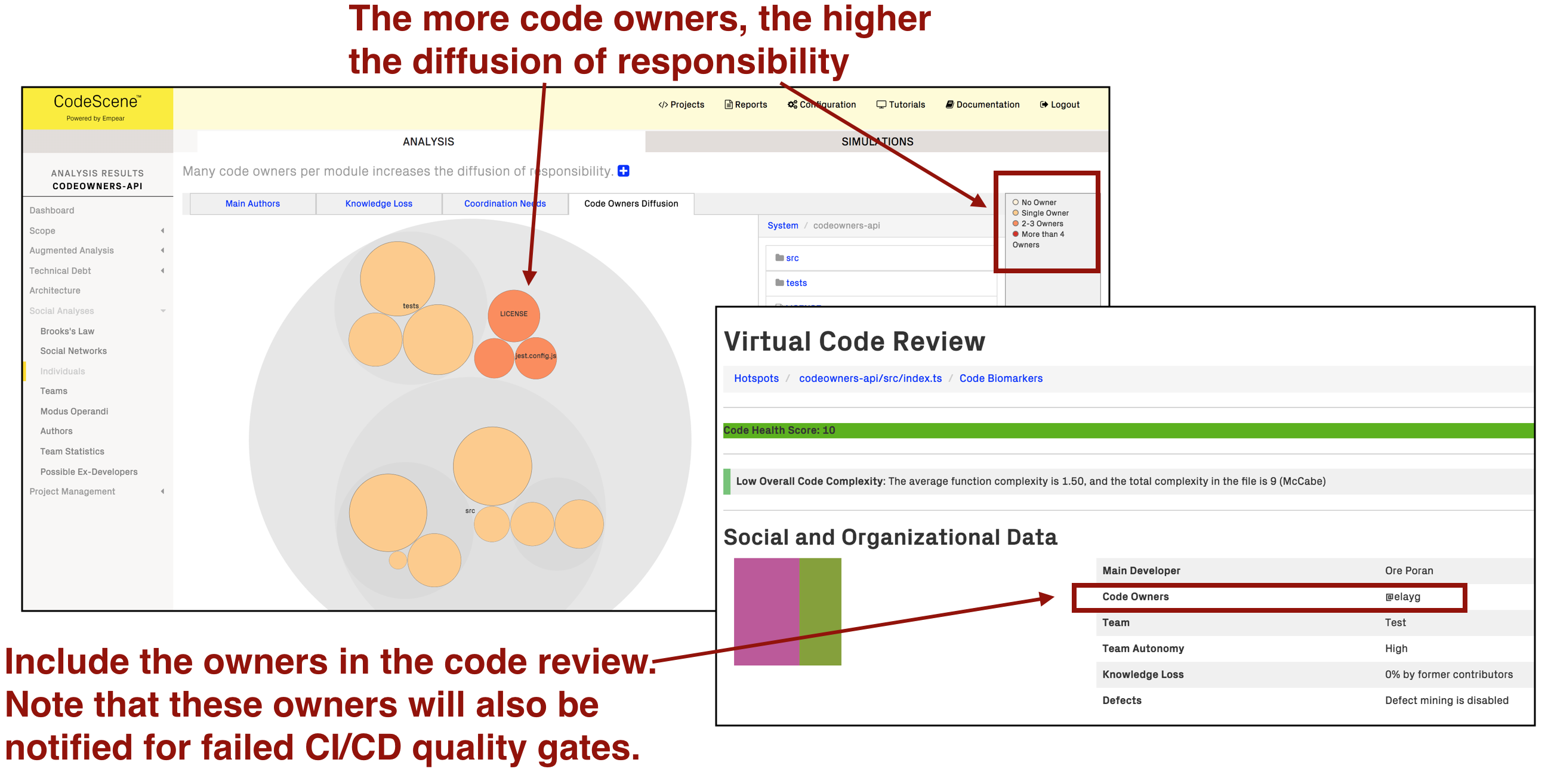
Fig. 149 CodeScene visualizes the code owners.¶
The main use case for this information is to:
Ensure that no critical parts of your code lacks ownership.
Ensure that your hotspots have a clear and strong ownership. In particular, you want to ensure that there’s a single owner for any hotspots in order to avoid diffusion of responsibility.
Notify Code Owners on Failed Quality Gates¶
CodeScene will also include the ownership information in case a CI/CD quality gate fails. You see an example in Fig. 150.
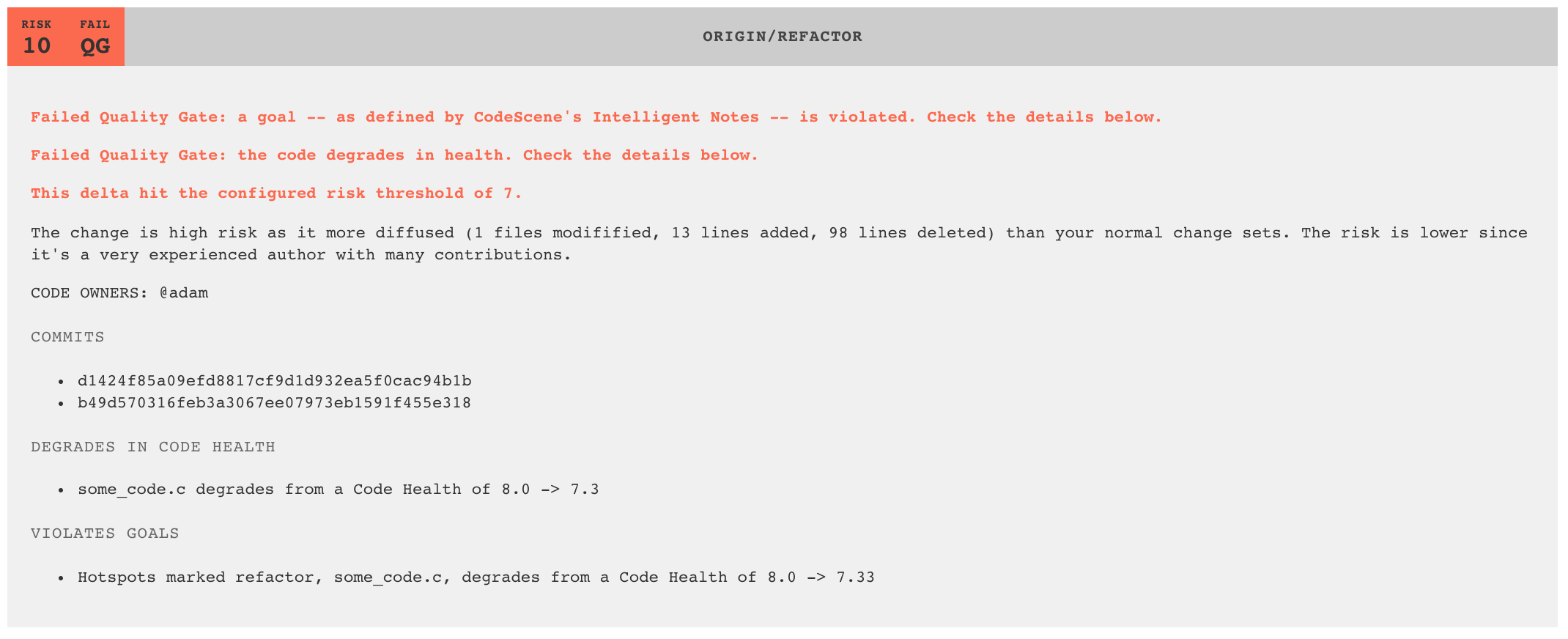
Fig. 150 CodeScene notifies code owners when a quality gate fails.¶
Uncover the Knowledge Loss in your Codebase¶
Knowledge loss represents code that is written by a developer who is no longer part of your organization or project. You use this information to reason about the knowledge distribution in your codebase and as part of your risk management since it is an increased risk to modify code we no longer understand. In addition, you can also use the analysis pro-actively to simulate the consequences, in terms of knowledge loss, of planned organizational changes.
The Knowledge Loss analysis will accumulate the contributions of all developers that you have marked as Ex-Developers in your configuration (see Configure Teams and Developers). Those parts of the codebase that are dominated by Ex-Developers are marked as red in the knowledge loss visualization. Fig. 151 shows an example from an organization where some core developers have left.
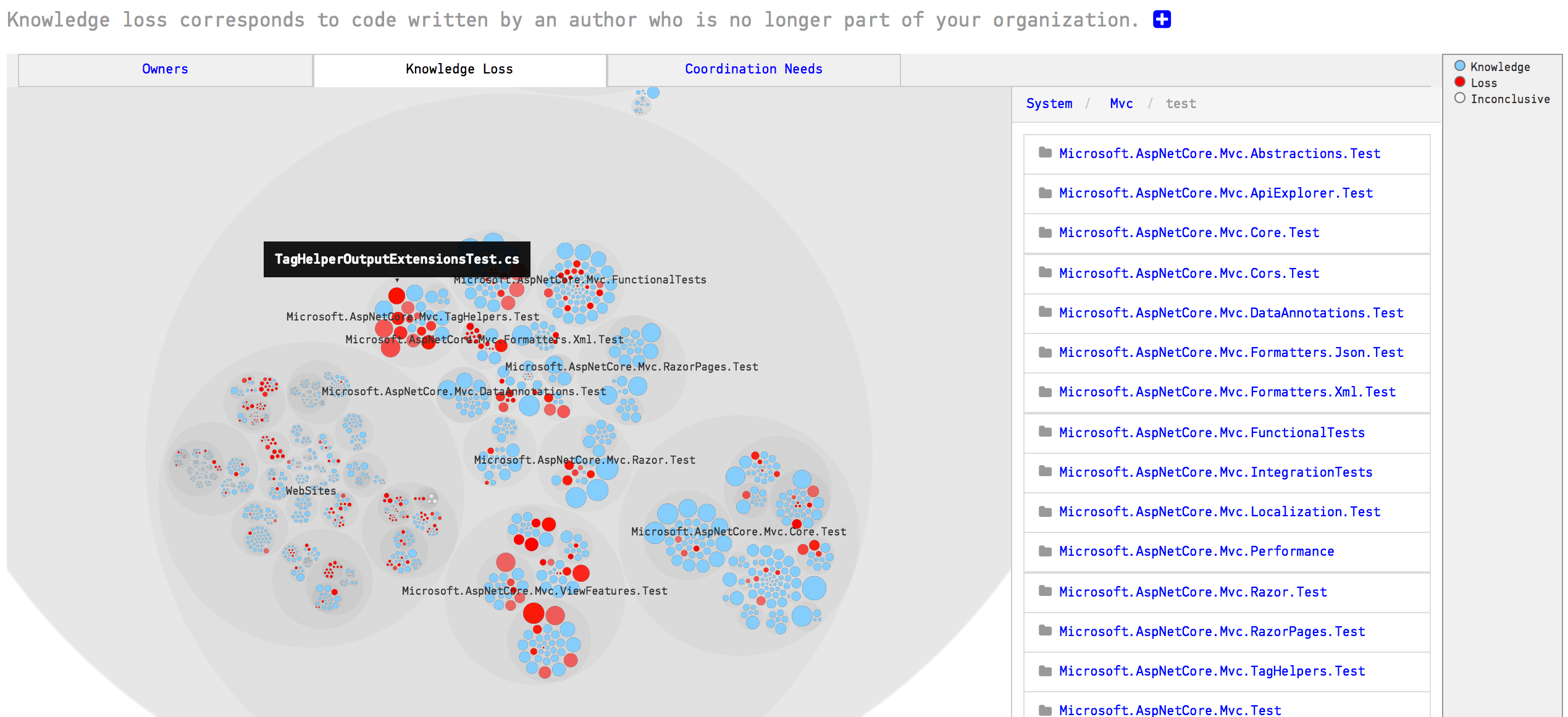
Fig. 151 An example on a knowledge loss analysis.¶
To inspect the knowledge loss you just click on a file, as shown in Fig. 152.
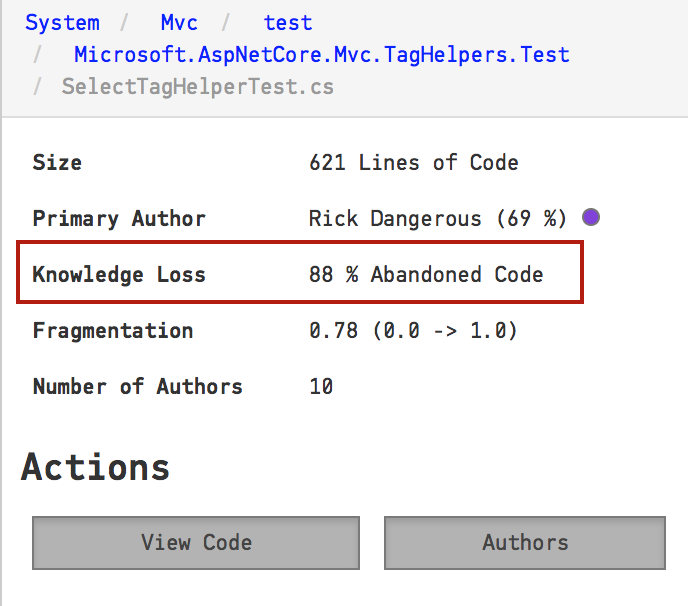
Fig. 152 Inspect the detailed knowledge loss of a file.¶
Note that there’s a special label in the knowledge visualization: Inconclusive. Inconclusive means that CodeScene cannot determine the original author of a piece of code. This is something that happens if you run a knowledge analysis on a shorter time span than the total lifetime of a codebase. CodeScene tracks moved and renamed content, but in doing so it depends on the underlaying object model of Git. So in the rare cases where copied content doesn’t get detected as such, the code may show up as inconclusive.
Use knowledge loss as a simulation¶
There are several uses for the knowledge loss information. In retrospect, you use it as part of your planning and risk management since it is an increased risk to modify code we no longer understand.
However, the knowledge loss analysis is much more powerful when used as a simulation. In this case you use CodeScene to simulate different scenarios and how they would affect your organization. Used this way, the knowledge loss analysis becomes a pro-active tool that helps you avoid unpleasant surprises in case a contractor leaves or a developer gets moved to a different project.
The guide in Team Planning with the On- and Off-Boarding Simulation describes how to simulate upcoming knowledge loss so that you can act on time.