Integrate Jira Information into CodeScene¶
CodeScene’s Jira integration is optional, but highly recommended if you have the information required for the analyses:
The Jira issue numbers are included/referenced in the commit messages.
You use labels and/or issue types in Jira to distinguish different kinds of work (e.g. Bugs, Features).
When present, CodeScene’s Jira integration lets you measure:
Accumulated costs per hotspot and sub-system.
Trends by work type, such as “Planned” versus “Unplanned” work.
CodeScene’s Jira integration lets you reason about the technical and organizational findings from a financial perspective. For example, how much time do you spend on defects in your top hotspots? What happens over time?
The use cases for the Jira integration are described in Project Management Analyses.
CodeScene’s Cost Model¶
CodeScene offers a breakdown of the development costs on three separate levels: file-, architecture-, and system-level. The file level corresponds to the hotspots, the architecture level accumulates costs on a component/service/module level, whereas the system level presents the cost trend as aggregated for all application code.
CodeScene distributes the derived costs proportional to the change impact. That is, the modules with most work in a specific issue get proportionally higher costs than modules that had less work. CodeScene automatically deduces this distribution.
The costs for multiple issues are then aggregated and split according to the type of work.
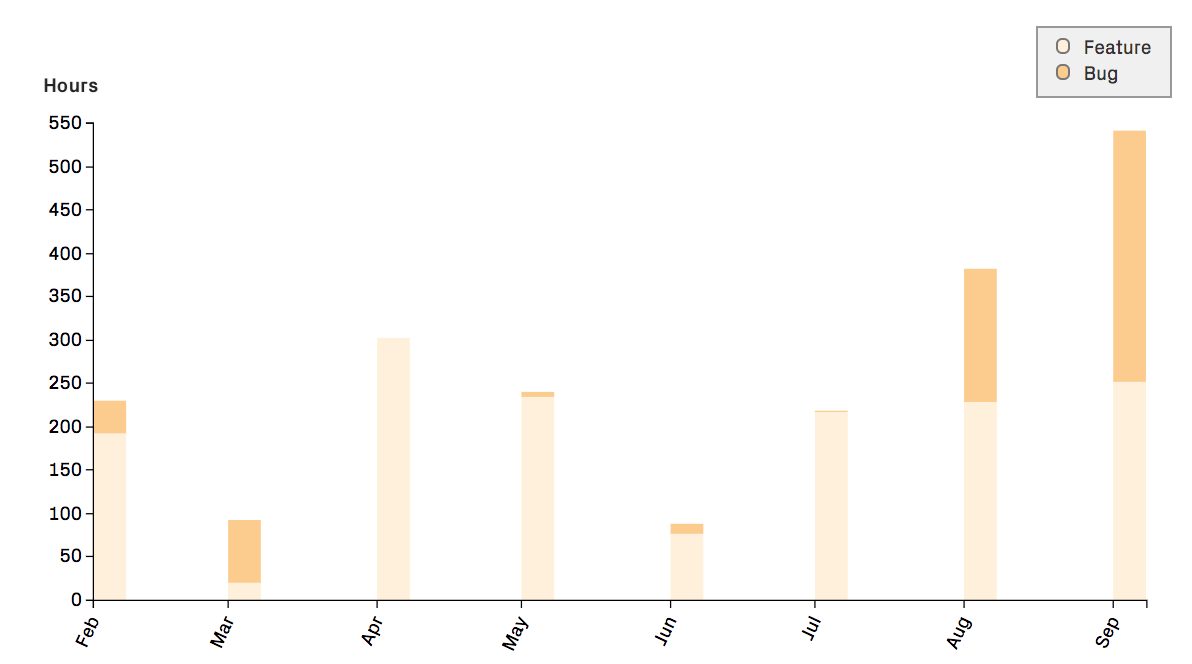
Fig. 26 CodeScene calculates cost trends on a file-, architecture-, and system-level.¶
Connect CodeScene to Jira¶
Previously, a separate service was required to connect CodeScene to Jira. Thi is no longer necessary because CodeScene can now connect directly to the Jira API. If you are still using the CodeScene Jira plugin, the documentation is available here: The CodeScene Jira integration service. However, we recommend using the new direct connection which also provides access to the latest analysis features.
Jira configuration is per project. Go to the “Project Management Integration” tab in your project’s configuration. Select “Jira” and click on “Save Configuration”:
Fig. 27 Start by selecting “Jira”¶
When you save the configuation, the form for configuring your Jira connection will appear:
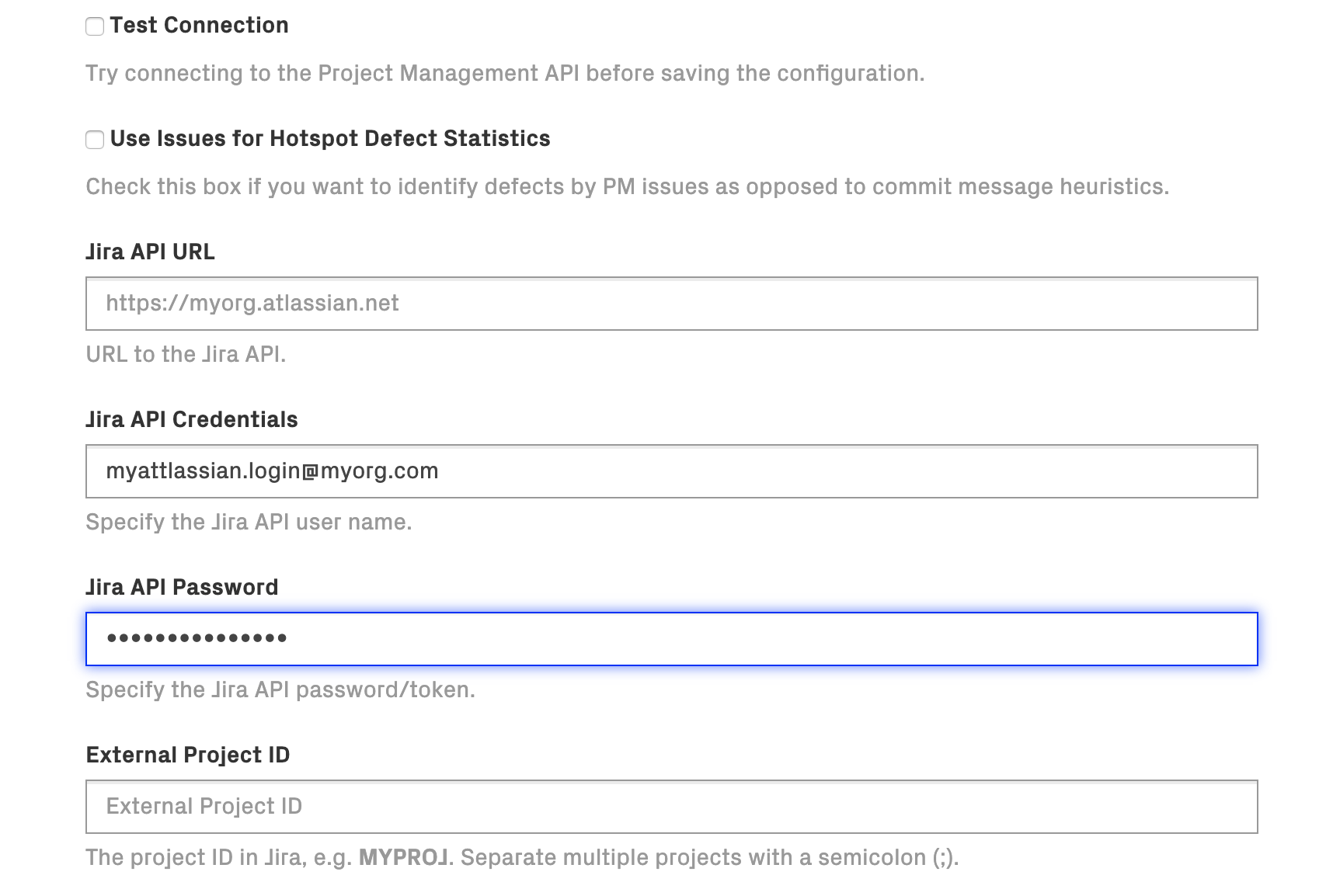
Fig. 28 Jira configuration options¶
Fill in your Jira credentials here. We recommend using a Jira API token as the password. External Project ID is the Jira identifier for your project.
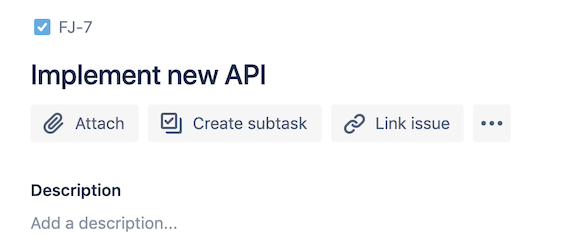
Fig. 29 “External Project ID” would be FJ¶
If an issue in your project looks like this, the External Project ID would be FJ.
Submitting the form with the “Test connection” box checked will cause CodeScene to immediately attempt to connect to your Jira provider.
When Use Issues for Hotspot Defect Statistics is checked, CodeScene will rely on Jira information for identifying defects rather than matching strings in commit messages. This affects how CodeScene compiles statistics related to the frequency of bugs in a codebase.
The remaining fields concern how CodeScene will interpret the Jira issues in your project.
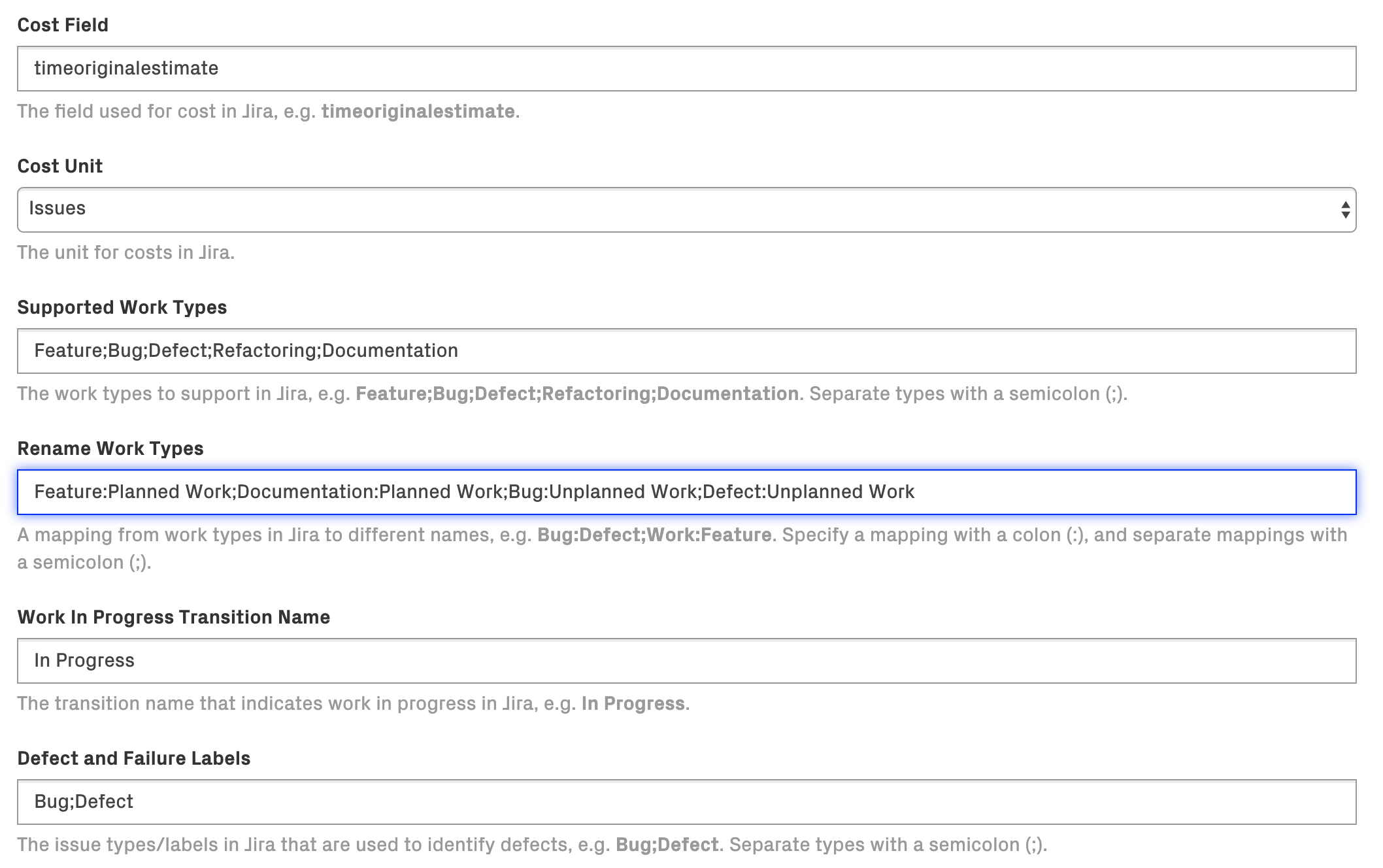
Fig. 30 These fields determine how your data will be applied to the project¶
Cost Field and Cost Unit tell CodeScene how to calculate costs. There are four strategies which correspond to the possibilities in the Cost Unit field:
Cycle Time in Development: the number of hours from the time an issue entered a specific Jira state until the last commit is done on this issue. The cycle time is adjusted for the number of hours in a typical work day. That is, a cycle time of 3 days has a cost of 3 * 8 hours. The Cycle Time option is the recommended default model since it lets CodeScene calculate costs as opposed to rely on time reported in Jira, which is often incorrect, incomplete, or both.
Issues: the number of issues associated with a given file or architectural component. Use this to get a summary but without the detailed costs.
Points: the cost of an Issue in /Story points/. Use this option if you keep track of story points and use them to communicate within the organization.
Minutes: the cost expressed in time. This method requires that time has been reported on the specified cost-field in JIRA. Use this option if you have accurate data in JIRA on how much time you have spent on each issue.
To use Issues or Cycle Time in Development, it is not necessary to configure Cost Field. For Points or Minutes, see the sections Using Story Points as Cost Estimation in Jira and Using Reported Time as Cost Estimation in Jira below.
To use Cycle Time in Development, you need to configure a Work In Progress Transition Name. This should be the name of the Jira status that indicates that the development work has started. Often, this is the “In Progress” or “In Development” state.
The Supported Work Types should correspond to the different kinds of issue labels defined in your Jira project, in a semi-colon separated list. Please note that only types with the listed labels/type will be included in the analysis.
The Rename Work Types field allows the work types to be mapped to different analytical categories that you can define yourself. How you do this depends on the type of analysis you wish to perform.
When looking at cost trends, the most interesting distinction is typically between Planned- versus Unplanned Work. When available, the Jira labels will be translated to the specified label before being sent to CodeScene. For example, if your Jira project contains Feature and Documentation labels, like in the illustration above, these can be categorized together as Planned Work, while Bug and Defect are treated as Unplanned Work; the Refactoring label – which doesn’t have a translation – will be sent as is. Mapping labels this way can allow you to see more meaningful trends. You are free to map labels however you like depending on your analytical needs.
The Defect and Failure Labels pecify the JIRA labels and/or JIRA Issue Types that will be regarded as defects. Note that this is independent from the Supported Work Types configuration (eg. a label added here will be used even if it is not present in Supported Work Types)

The Ticket ID Pattern is a regular expression that tells CodeScene how to extract the Jira ID from commit messages. For most projects that use the standard PROJ-123 format, the default pattern will work: (.+-d+).
Using Story Points as Cost Estimation in Jira¶
When JIRA is configured to use Story Points as estimate for stories, epics, and possibly other issue types, the points will be added in a custom field JIRA creates for this purpose when Story Points is configured. The custom field will get a generated id. In order to be able to configure the PM integration service correctly, this custom field needs to be identified. The following command (against the JIRA service) using curl and jq will filter out the custom field for a project with the key CSE2 (see Atlassian Answers):
$ curl -u 'jirauser:jirapwd' \
'https://jira.example.com/rest/api/latest/issue/createmeta?expand=projects.issuetypes.fields'\
|jq '.projects[]|select(.key=="CSE2")|.issuetypes[]|select(.name=="Story")|.fields|with_entries(select(.value.name=="Story Points"))'
{
"customfield_10006": {
"required": false,
"schema": {
"type": "number",
"custom": "com.atlassian.jira.plugin.system.customfieldtypes:float",
"customId": 10006
},
"name": "Story Points",
"hasDefaultValue": false,
"operations": [
"set"
]
}
}
You can verify that this is in fact the field with the Story Points. Say that you already have a story CSE2-257 with Estimate: 4 filled in, then you can find the field name and verify the points with this command:
$ curl -u 'jirauser:jirapwd' \
https://jira.example.com/rest/api/latest/issue/CSE2-257
{
...
"fields": {
...
"timetracking": {},
"customfield_10006": 4,
Using Reported Time as Cost Estimation in Jira¶
When using Minutes instead of Points, CodeScene searches Jira for the configured field name, usually timeoriginalestimate, having a non-empty value:
curl -u 'jirauser:jirapwd' \
'https://jira.example.com/rest/api/latest/search?jql=project=CSE2+and+timeoriginalestimate!=NULL'
Custom fields, however, cannot be searched like regular fields. Unfortunately, it seems it’s not possible to just use the complete field name, customfield_10006:
$ curl -u 'jirauser:jirapwd' \
'https://jira.example.com/rest/api/latest/search?jql=project=CSE2+and+customfield_10006!=NULL'
{
"errorMessages": [
"Field 'customfield_10006' does not exist or you do not have permission to view it."
],
"errors": {}
}
Instead, there is a variant that uses cf[ID] (see the JIRA documentation), where ID is the id of the custom field, in our case 10006. Note that the brackets must be URL-encoded, so cf[10006] turns into cf%5B10006%5D:
curl -u 'jirauser:jirapwd' \
'https://jira.example.com/rest/api/latest/search?jql=project=CSE2+and+cf%5B10006%5D!=NULL'|jq .
This means that the code for sync must detect whether a custom field is being used, extract the id, and use that in the query.