Code Age¶
Code Age is a much underused driver of software design. In this guide we’ll cover how you interact with the analysis results and how you use the presented information to guide your architectural decisions.
Drive to Stabilize¶
Code evolve at different rates. As you’ve learned in the Hotspots Guide (see Hotspots), some parts of your codebase tend to change much more frequently than others. The Code Age Analysis gives you another powerful evolutionary view of your system. It’s a view that helps you evolve your codebase in a direction where the system gets easier to maintain and more stable.
The age of code is a factor that should (but rarely do) drive the evolution of a software architecture. In general, you want to stabilize as much code as possible. A failure to stabilize means that you need to maintain a working knowledge of those parts of the code for the life-time of the system.
How do we measure Code Age?¶
CodeScene measures code age per source code file (or any content, actually). We define the age of code as “the time of the last change to the file”. Note that this means any change. It doesn’t matter if you rename a variable, add a single line comment or re-write the whole module. All those changes are, in the context of Code Age, considered equal.
This definition is fairly rough and in the future we’re likely to take the amount of change to a file into account when calculating age. But for now, age is that time since the last change. And the resolution is months.
Inspect your Code Age Distribution¶
The age distribution graph shows how much of your codebase that you have managed to stabilize.
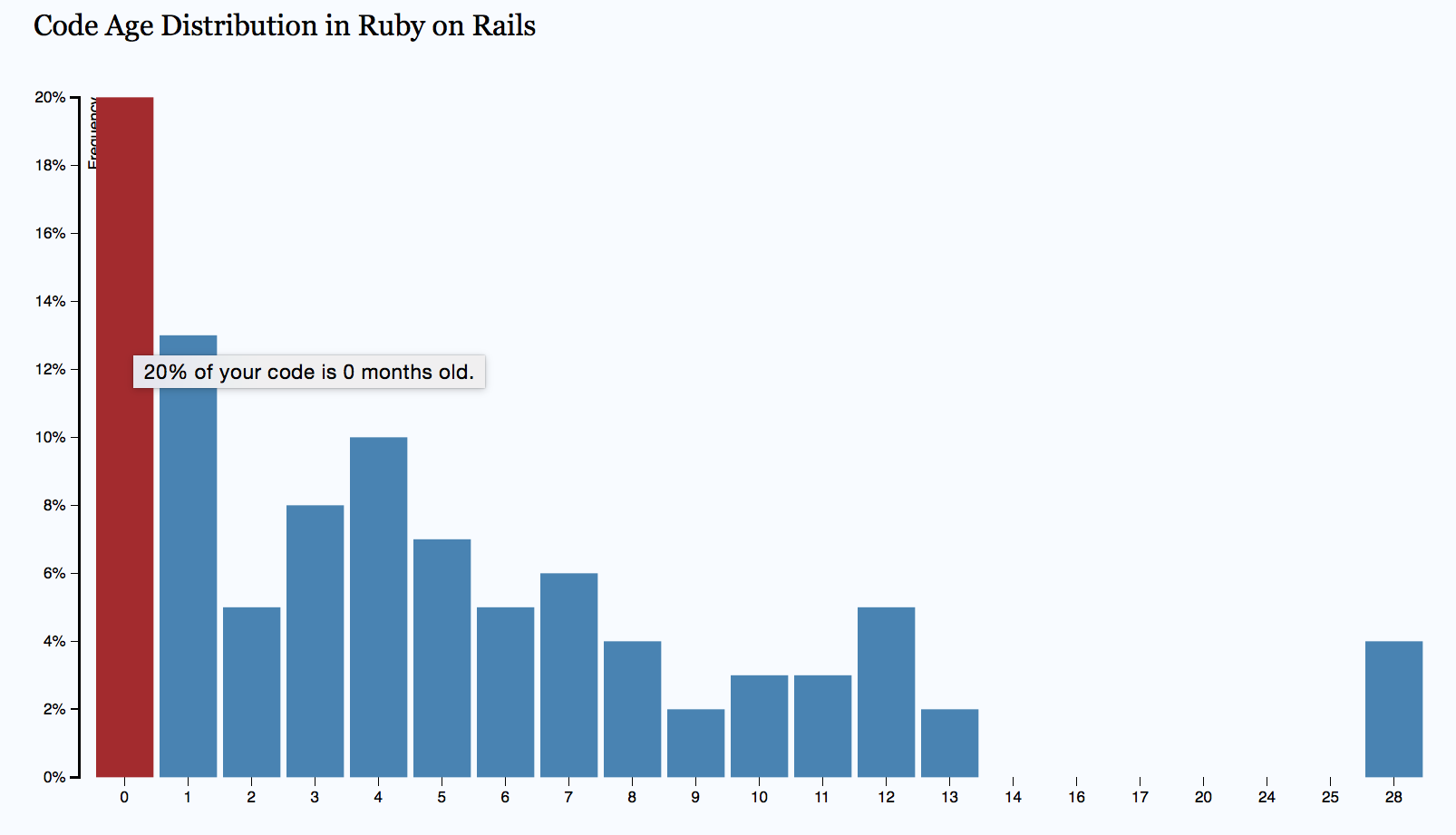
Fig. 90 An example of code age distribution.
The example graph in Fig. 90 shows a codebase under heavy development. As you see, 20% of the source code files have been modified the past month. Here’s how you use this information:
- See how much of the code you manage to stabilize.
- Identify sub-systems that have become commodities.
Let’s discuss these two points. First of all, you want to stabilize as much code as possible. Stable code means that its quality is known. It also limits the size of the codebase where a developer has to maintain an active mental model of the code. New code (0-2 months old) is of course where the current development happens and you expect some activity here; a system that doesn’t change is a system that no one uses. What you want to look out for is everything in between. That is, the code that’s neither particularly old nor do we need to work with it on a monthly basis.
The reason we’d like to avoid having code that is neither old nor new has to do with human forgetting. Such code is old enough that the original programmers are unlikely to remember the details. If we need to dig into code that we no longer remember well, we pay a high price. So please watch out for a codebase where you have a flat distribution.
The second use case for Code Age Distribution is to identify commodities. A commodity is code that’s been stable for a long time. You see an example from the development of the Clojure programming language in Fig. 91.
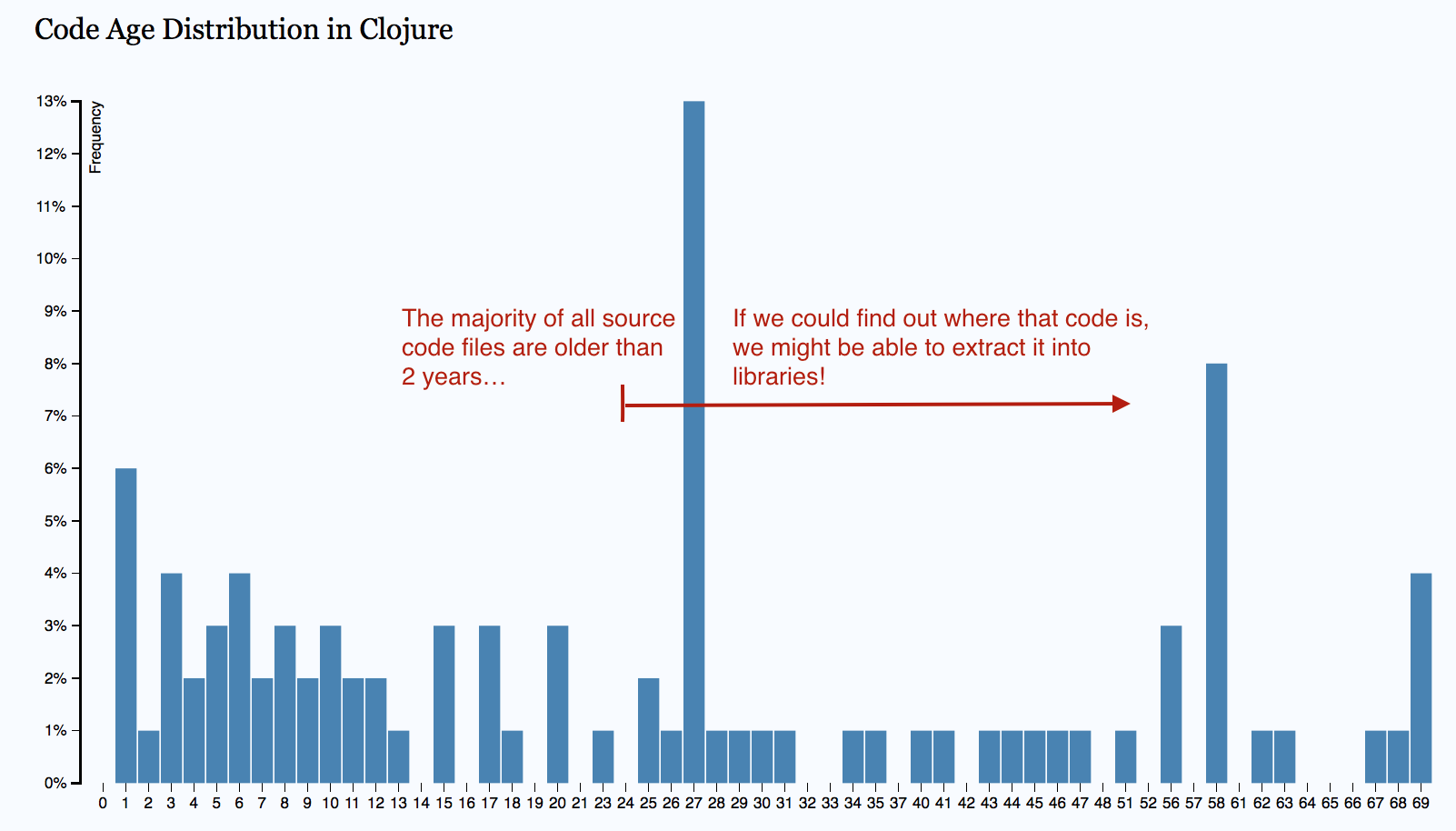
Fig. 91 Code age distribution in Clojure.
This is a good starting point; If you have a lot of code, as in the distribution in Fig. 91, that you haven’t modified in years, there’s an opportunity to drive your software architecture in a leaner direction. To do that we need to get more information. We need to understand where in the codebase those stable parts are. That information is provided in the Age Ring View that we discuss below. Before we get there, however, we need to be aware of some possible biases.
Possible sources of Bias in the Age Distribution¶
As noted above, code age is measured since the time of any change to a file. That means, if you re-organize your codebase by moving source code files to different folders, your code will appear much younger than it actually is.
Unfortunately we do not provide a way to counter this bias in the current version of CodeScene. But please stay tuned for future versions where we’ll solve this.
Identify Stable and Unstable Sub-Systems in the Age Ring View¶

Fig. 92 Annual rings of a tree.
So, the Code Age Distribution told us that we’ve a lot of code that we haven’t modified in a long time. The Age Ring View lets you identify where those stable parts are.
Think of the Age Ring View as the annual rings of a tree, but for code. You specify a cut-off point for the age you’re interested in and inspect the resulting view.
You select the cut-off point based on the Age Distribution in your codebase. The cut-off point should mean something in your context. For example, we noted above the the Clojure codebase has a lot of code that’s older than two years. Fig. 93 hows how we find that code.
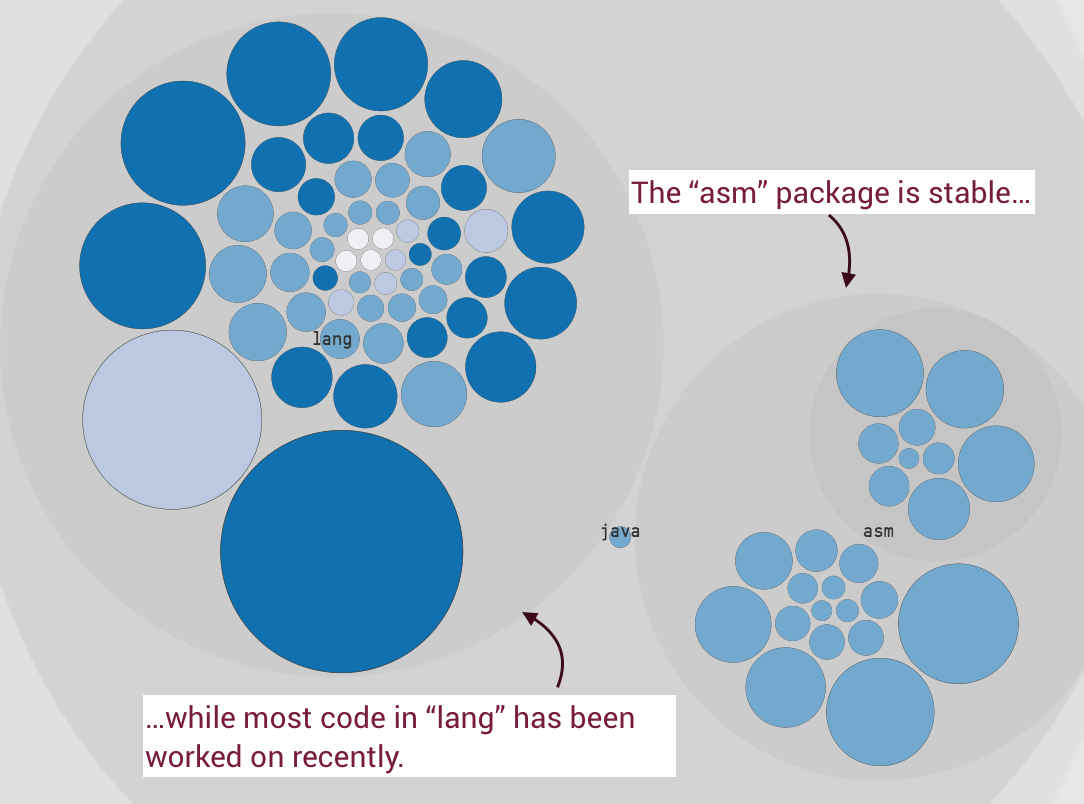
Fig. 93 Stable code in Clojure.
Extract Stable Packages as Libraries¶
Once you’ve found stable packages you may want to consider to extract them as packages. If we transform stable packages into libraries we get a set of advantages:
- Stable code lets us maintain long-term cognitive models: The developers now only needs to focus on the API of these packages.
- Minimize cognitive load for new developers: As a direct consequence, new developers have less code to understand as they enter your codebase. Age is not something that’s visible in the code itself and it’s thus hard to know if I, as a developer, have to understand that part of the system or not.
- Know where extra tests add most value. You may want to write a set of high-level automated checks around your extracted packages. Those test scripts would capture your understanding of the package and ensure your expectations are correct. Since the code under test is stable, your tests will be stable as well. The reason you have them is so that you can ensure that you don’t break existing code when you someday have to modify a part that is a known commodity in your system.
- Know which tests you don’t have to run in each build. Once you stabilize code, you don’t need to run the unit-, function-, integration-tests for that part in every single build. That means you can shorten your delivery cycle by ignoring tests in the parts of the system that haven’t been changed for ages.
Identify Parts That Fail to Stabilize¶
Sometimes you’ll find a package (component, sub-system, etc) whose parts change at different rates as in Fig. 94
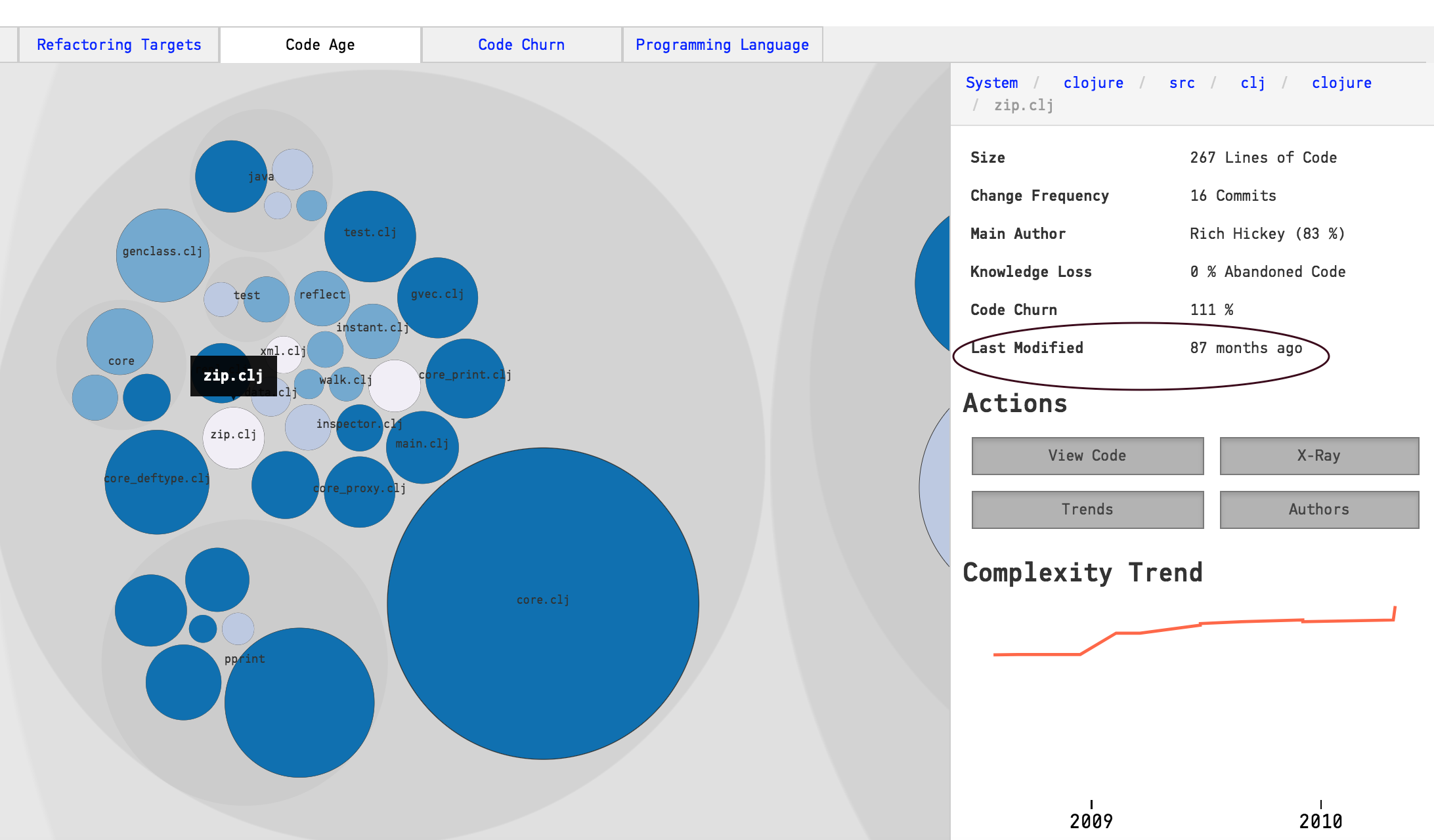
Fig. 94 Code that stabilizes at different rates.
Code in the same package/subsystem that change at different rates is a warning sign. It either means that 1) some of the code is of lower quality and we need to patch it often or 2) the parts model different aspects of the problem domain.
Our general recommendation is to try to split packages by the age of the elements contained within them. That is, organize your code by age. Consider the same strategy for larger files that fail to stabilize. Split their content into several, cohesive files. That way, you’ll get information on what parts of the problem domain that are volatile and the parts that are stable.
Use Code Age to assess Knowledge Loss¶
A Code Age analysis has more usages than just software architecture. If you have areas of Knowledge Loss in your codebase you can use Code Age to assess how severe the loss is. Is the abandoned code a part that has been under active development recently? In that case, I would worry. If not, things look better. Sure, you get a knowledge gap with each developer that leaves, but that gap is in a part of the system that you haven’t been working on for a long time. Besides, since that code is so old, it’s also likely that the original developers, even if they were still present, would have a learning curve themselves.