Project Configuration¶
Specify the Git Repository to Analyze¶
Your first step is to tell CodeScene where your code is. You have three different ways of doing that:
1. Specify the paths to your local, physical Git repository, which has to be on the same machine as CodeScene runs on. The path you specify has to be to the root folder of your repository (i.e. the folder that contains your .git folder).
2. Let CodeScene scan a folder on your file system for repositories to analyze. You’ll be prompted with the results and are free to ignore the repositories you want to exclude. This option is useful in a multi-repository project.
3. Specify the URLs to Git remotes. CodeScene supports the protocols specified by Git clone: ssh, http, and git. CodeScene will clone the remotes to a local folder that you specify in the configuration as illustrated in Fig. 76. Note that CodeScene will re-use a local Git repository if there’s an existing clone on the path you specify. Also note that you need to have a an ssh-key that lets the CodeScene (system) user access your remote repositories.
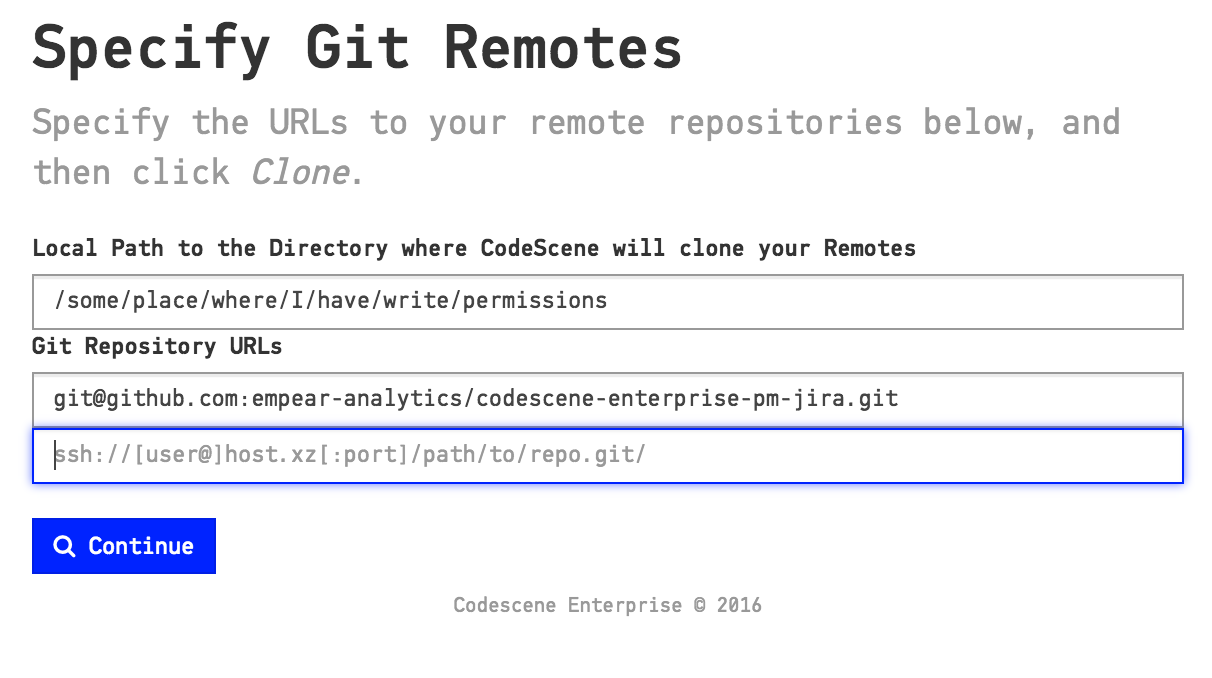
Fig. 76 Let CodeScene clone your Git repositories through their URL.
Finally, note that you cannot mix local repository paths with URLs to remote Git repositories in a single analysis project.
Analyze Projects organized in Multiple Git Repositories¶
There’s a recent trend towards organizing the source code of larger systems in multiple Git repositories. For example, you may have the code for your user interface in one repository, the code for your service layer in another repository and perhaps even a Git repository dedicated to your back end mechanism. Another typical example is Microservices where each service is deployed according to its own life cycle. In that case, organizations often chose to use one Git repository per service.
CodeScene supports an analysis of multiple repositories at once. All you have to do is to specify the paths to them:
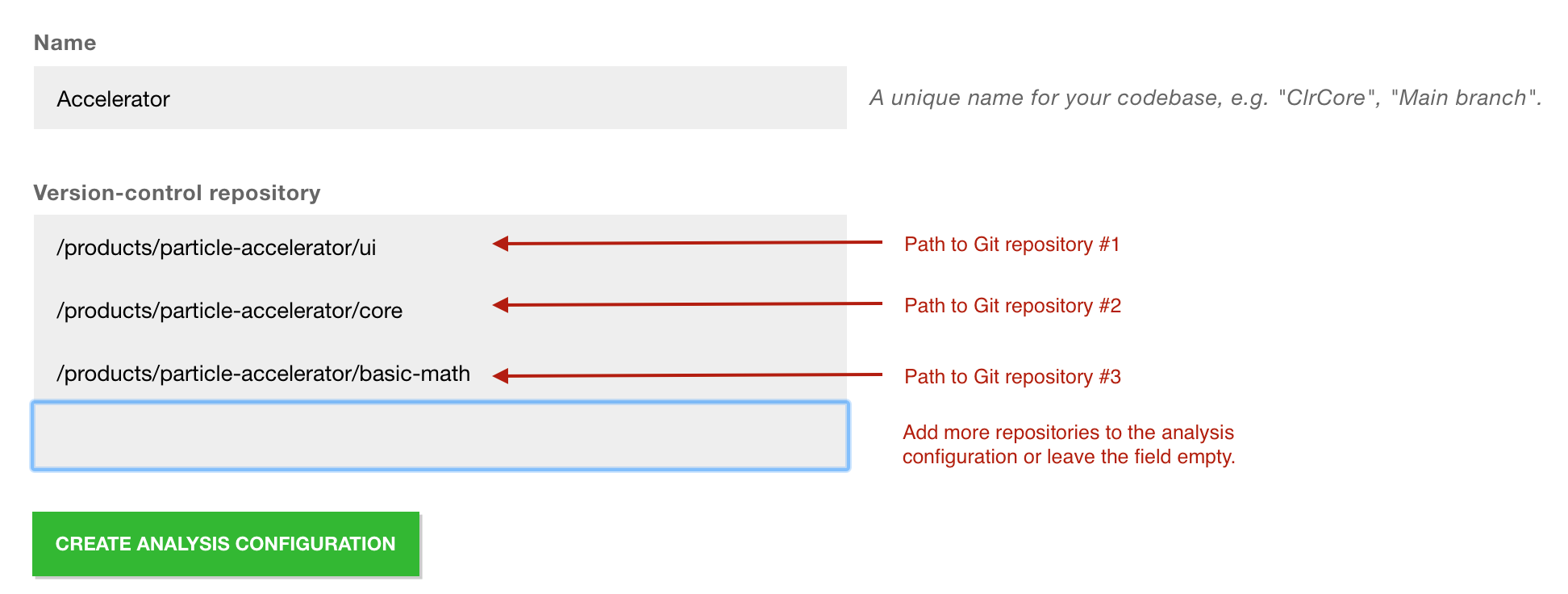
Fig. 77 Configuration of multiple repositories.
The screenshot above shows three repositories that belong to the same product. During an analysis, CodeScene will analyze the evolution of the code in all those repositories as though they were in the same physical Git repository.
You can specify as many repositories as you want and remove one at any time (just erase the text in that box). However, a word of warning: do NOT attempt to analyze unrelated repositories in the same configuration. First of all it’s a breach of the license agreement. Worse, you won’t get useful results since many of the basic metrics, like Hotspots, are relative metrics.
Auto-Import Repository Paths¶
Specifying one or two repositories by hand is straightforward. However, some systems consists of hundreds of repositories. In that case you want to use the auto-import feature.
The auto-import feature lets you specify a root path to where your repositories are located. Here’s what it looks like:
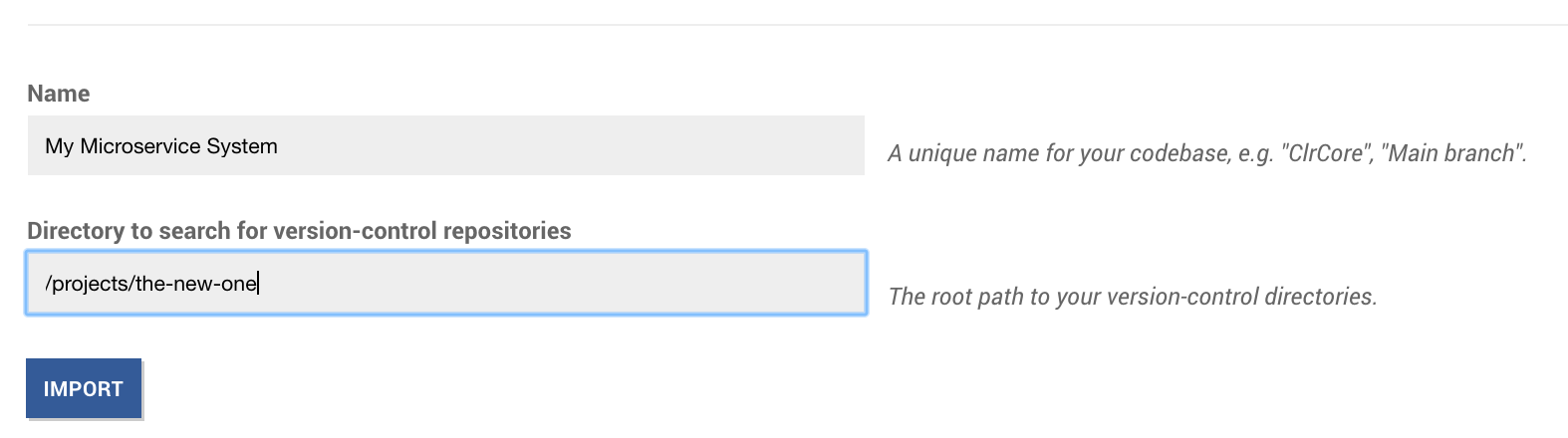
Fig. 78 Automate the import of multiple repositories.
CodeScene will scan the path you provide to discover any Git repositories. The discovered Git repositories are presented in a list. Note that you can add additional repositories manually or remove the once you want to exclude:
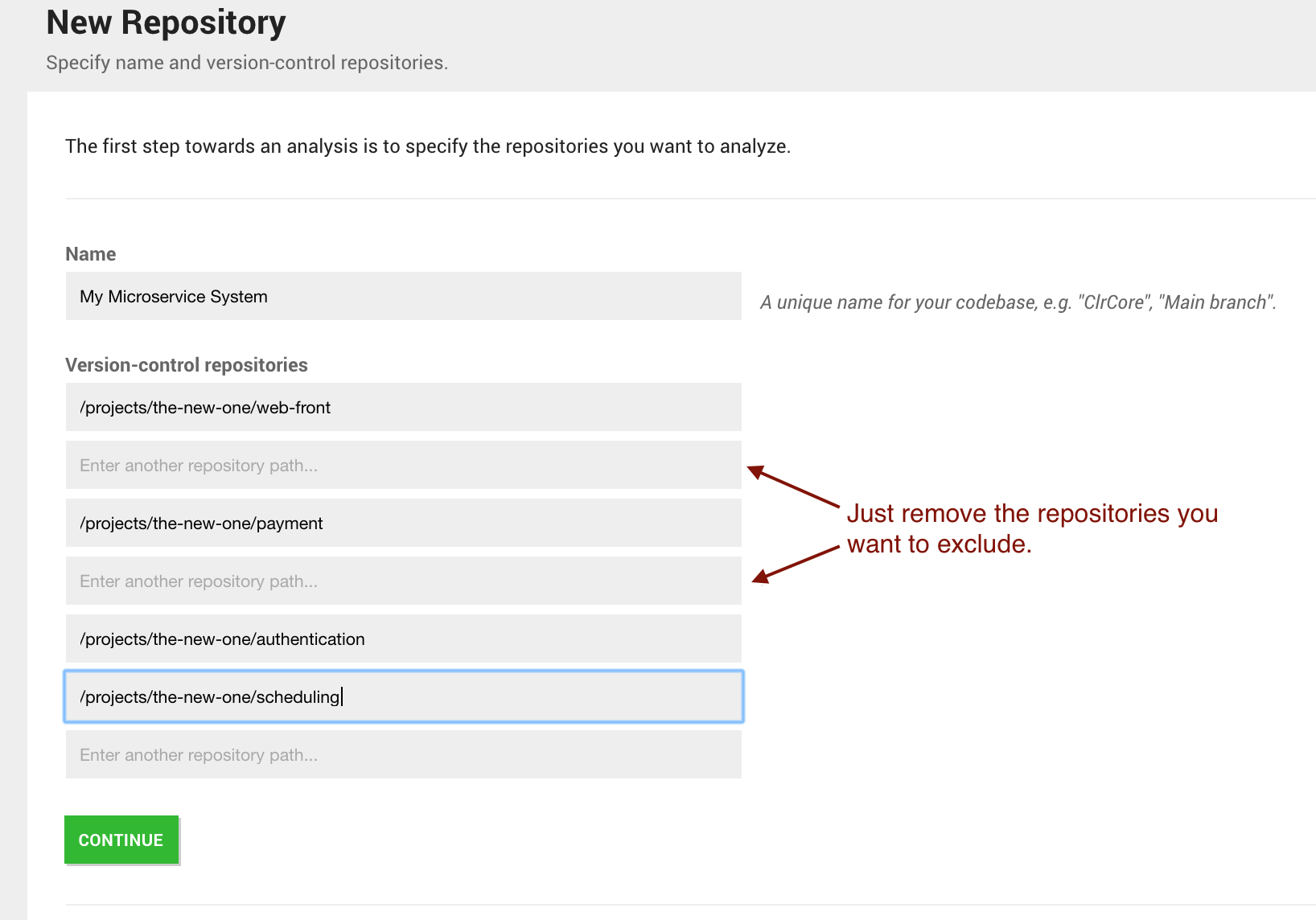
Fig. 79 The result of auto importing multiple repositories.
From here you just press Continue to proceed with the configuration of your analysis. The rest of the workflow is identical to the case where you specify repositories manually.
Measure Temporal Coupling across Multiple Repositories¶
The normal temporal coupling metric considers two files coupled if they tend to change in the same commits. This won’t work if your codebase is split across multiple repositories. Instead, you want to aggregate individual commits into logical commits. CodeScene supports two different strategies for aggregating commits:
- By Author and Time
- When you specify this option, the tool will consider all commits by the same author on the same day as a single, logical commit. This option is a heuristic that works well in the absence of a Ticket ID in your data.
- By custom Ticket ID
- This option uses an identifier in your commit headers. All commits that refer to the same identifier will be considered one logical commit.
The second option, By custom Ticket ID, is the preferred method. Fig. 80 shows the options in the repository configuration section Temporal Coupling.
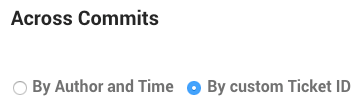
Fig. 80 There are two available strategies for aggregating commits.
To aggregate by custom Ticket ID, you need specify a Ticket ID Pattern, in
the Ticket ID Mapping section (see Fig. 81). The pattern
is used to extract the Ticket ID from the commit message. The example pattern
in Fig. 81 will extract all identifiers that start with the
text ISSUE- followed by at least one digit. For example, the commit
message ISSUE-42 will result in 42 as the extracted Ticket ID.

Fig. 81 Configure a pattern to extract a Ticket ID.
Note that CodeScene will still calculate normal temporal coupling on a single commit basis. You want that in order to spot unexpected dependencies between files in the same repository. The temporal coupling results for the logical commits discussed above are presented in a separate analysis view.
Exclude Files from an Analysis¶
An analysis will include all textual content in your repository. That means: you get an analysis of your build scripts, resource files, configuration files, test data, etc. While it’s a good practice to run an analysis of all content every now and then, there’s also the risk that you get too much noise in the analysis results. For example, you typically want to exclude auto generated content.
The Exclude Files option lets you specify a set of file extensions that will be excluded from your analysis:

Fig. 82 Exclude specific types of files.
CodeScene comes with a set of pre-defined exclusion patterns that should match the most common cases. You’re free to extend this set if you have additional file types that you want to exclude. Just remember to use a semi-colon (;) to separate each file extension you want to exclude.
Exclude Specific Files and Folders from an Analysis¶
You just learned how you can exclude certain types of files, no matter where they are located in the your codebase. But sometimes you’d like to exclude a particular file or, more often, a complete folder. For example, let’s say that you check-in third party code in your repository. You don’t want that code to obscure potential analysis findings in your own code.
There are two different ways to exclude complete folders and files:
- White list the content you want to include in the analysis. All other content will automatically be excluded.
- Black list the content you want to exclude.
You can specify both white- and black list content. The white listing will be applied first.
You specify a glob pattern to white list the content to include in your analysis as illustrated in Fig. 83.
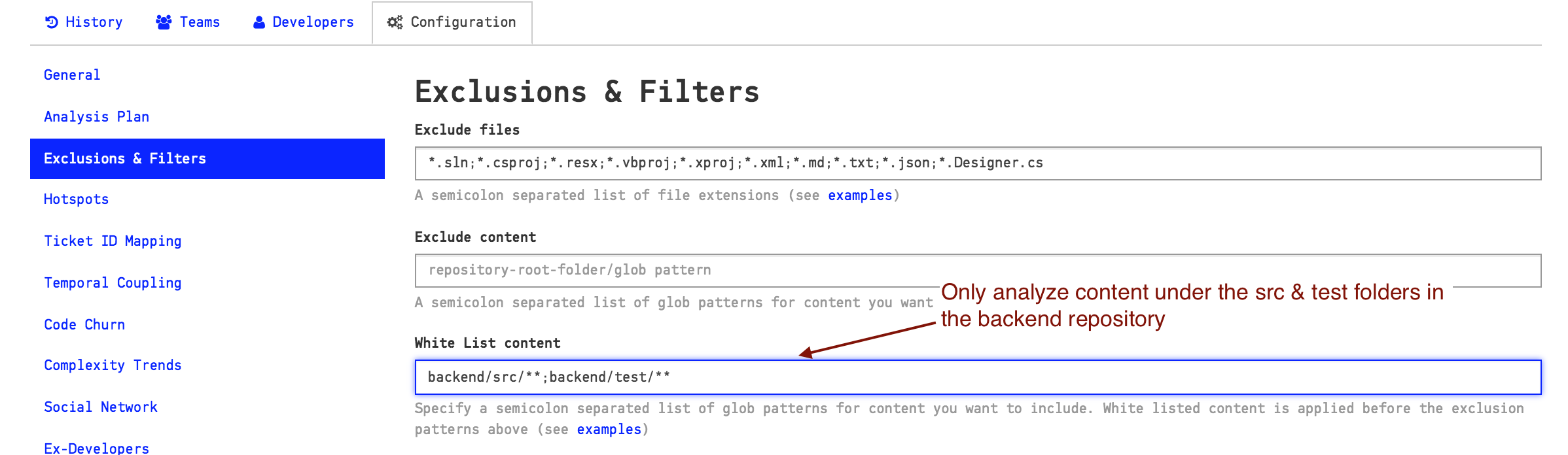
Fig. 83 Glob patterns to white list content.
You specify a glob pattern to Exclude Content from the analysis as illustrated in Fig. 84.
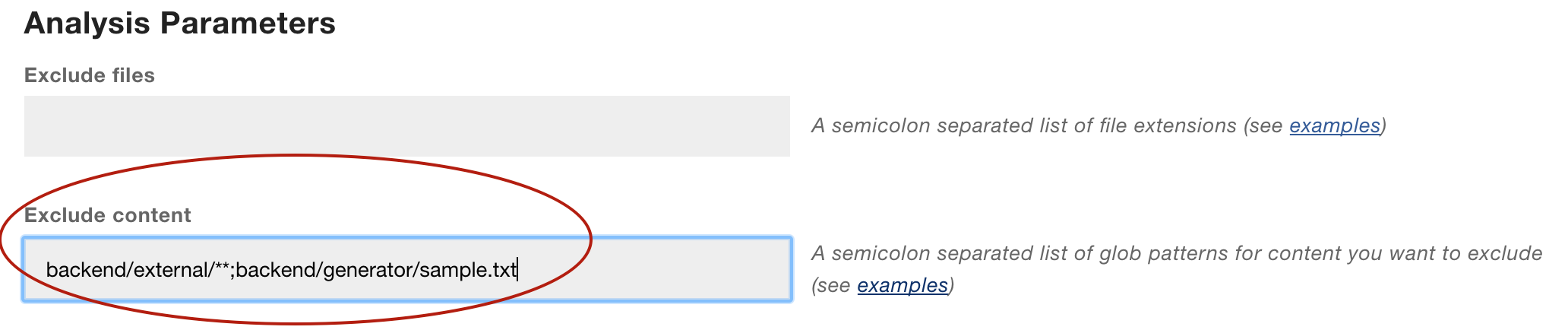
Fig. 84 Glob patterns to exclude content.
The example above will exclude all content under the external folder and the file samples.txt from the generator folder.
Note: You need to specify your exclusion paths using UNIX style path names. That is, use forward slashes as separators. Also note that the paths have to start with the name of your repository root. That is, if your Git repository is located in a folder named backend, as in the example above, you have to prepend that folder name to all your exclusion patterns. The reason for that is due to CodeScene’s support for multiple repositories where you have to be explicit about what repository you exclude things from.
There’s one exception to the rule that patterns have to specify the repository root. That’s the case when you want a pattern to apply across all repositories. For example, let’s say that you want to exclude all shell scripts in your test folder. In that case you specify a pattern like **/test/*.sh That is, your patterns are allowed to start with a wildcard too.
A Brief Guide to Glob Patterns¶
Glob patterns let you specify paths- and file names with different wildcards. CodeScene supports the following wildcards:
1. *: A single asterisk matches any string of characters. Use it to exclude or while list particular files. For example *.h will exclude all files with extension h. You can also use the single asterisk to specify glob patterns that apply to all your repositories in a multi repository analysis project. For example, the glob pattern */version.txt will match (and possibly exclude) the version.txt files at the top level of each of your repositories.
2. **: The double asterisk matches whole paths/directories. You use the double asterisk to exclude or white list content independent of the content’s location in your codebase. For example, the pattern myrepository/**/*.h will match all files with extension h in any directory in your repository. You can also use the double asterisk to match exclude or white list whole folders. Let’s say we want to exclude all our unit tests from an analysis and that those tests are located in the repository ‘coolstuff’. Here’s a pattern for that: coolstuff/test/**.
- ?: The question mark matches a single character.
Please note that all glob patterns are specified using UNIX style path names. That is, if you’re on Windows you do not use backslash to separate directory names, but rather the UNIX style forward slash. That is, the directory SomeRepo\Test is excluded by specifying SomeRepo/Test/**.
Specify An Analysis Period¶
CodeScene lets you specify an analysis period as illustrated in Fig. 85. That is, how much of your repository history do you want to analyze?
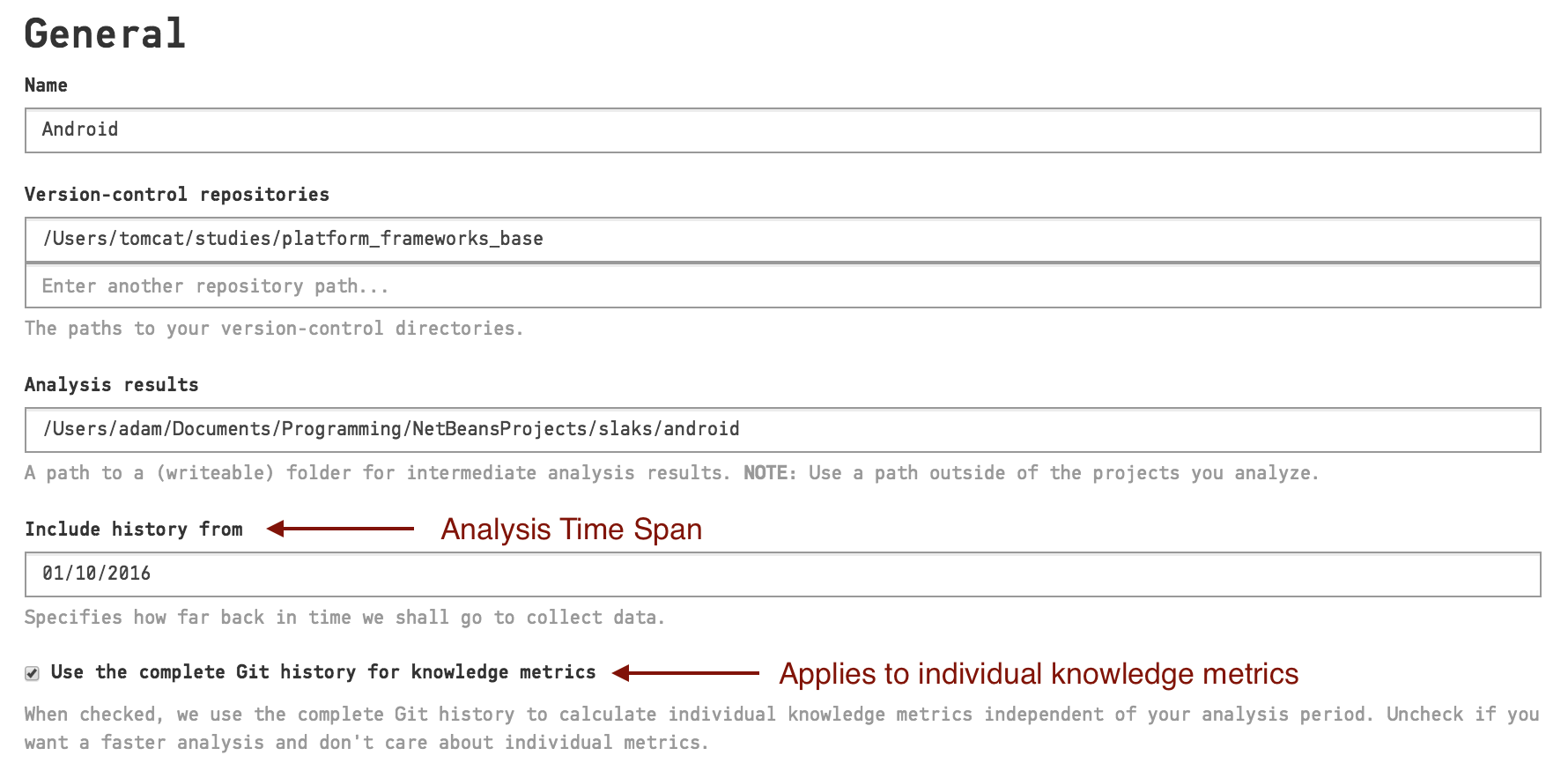
Fig. 85 Specify how far back in time you want CodeScene to analyse.
The actual analysis period you select depends on several factors:
- The activity in your project: Select a short analysis period, like 6 months, in a codebase with a lot of development activity.
2. The information you want: If you want an overall view of potential maintenance problems, we recommend that you use a longer analysis period like a couple of years. If, on the other hand, you want to identify recent modifications to the codebase, your analysis period could be as short as the length of your iterations (2-3 weeks).
3. You have recently re-structured the codebase: In this case you want to specify an analysis start date after the re-structuring. The rationale is that the history is probably not as useful since you now have a new structure of your system. Use that as the cut-off point.
By default CodeScene will use two different analysis periods depending on the type of information it analyses:
- Technical information and Team information uses the specified date.
- Individual knowledge metrics use the full history of your repository.
The rationale is that analyses on the level of individual developers, like knowledge maps and knowledge loss, need to take the full history of the codebase into account in order to be accurate. You can disable this behavior and use the specified date for all analyses by unchecking the box “Use the complete Git history for knowledge metrics” (see Fig. 85).
Finally, please remember that selecting an analysis time span depends on the questions you have. As such your choice depends on your context and is more of a heuristic than a science. Always start with an analysis of the full history when in doubt.
Visualization Options¶
CodeScene is capable of analyzing large codebases consisting of millions lines of code. However, the web browser you use to view the results isn’t always that performant. In particular, if you have a repository with several thousands of files, the Hotspot and Knowledge visualizations will become slow and painful to navigate.
If you experience that problem, consider to increase the thresholds in the Visualization section, shown in Fig. 86.

Fig. 86 Exclude small files from a visualization.
The first option simply excludes files smaller than your specified size from the visualizations. The second option excludes files that haven’t changed more often than the threshold you enter.
The rationale is that in a system of several thousand files, the small ones (1-100 Lines of Code) are probably not the most interesting ones. Thus, these should be safe to exclude.
Note that the visualization algorithm performs some checks to ensure that a hotspot, no matter how small, is included anyway so that you don’t miss some important result. Also note that the exclusion only applies to the visualization - the code is still included in the analysis.